
리눅스 명령어에는 다양한 필터가 존재한다. (grep이나 sed 등등..)
그러나 조금 더 복잡한 패턴을 검색에 사용하고 싶을 때 정규표현식을 사용!
ex) can, man, fan, dan, ran, pan 중 can, man, fan만 검색하고 싶다면 [cmf]an 으로 입력 가능
ex) 휴대전화번호 010-xxxx-xxxx을 검색하고 싶은 경우
010-[0-9]{4}-[0-9]{4} 또는 010-\d{4}-\d{4}
- [0-9]와 \d는 같은 개념
- \d{4} 숫자가 네 번 연달아 등장해야 함
Regex patterns

- \d : 숫자 하나를 지정함
- \D : 숫자가 아닌 문자를 지정
무튼 위 정규표현식을 연습하기 위해 다음 사이트에서 exercise를 풀어보았다.
RegexOne - Learn Regular Expressions - Lesson 1: An Introduction, and the ABCs
Regular expressions are extremely useful in extracting information from text such as code, log files, spreadsheets, or even documents. And while there is a lot of theory behind formal languages, the following lessons and examples will explore the more prac
regexone.com
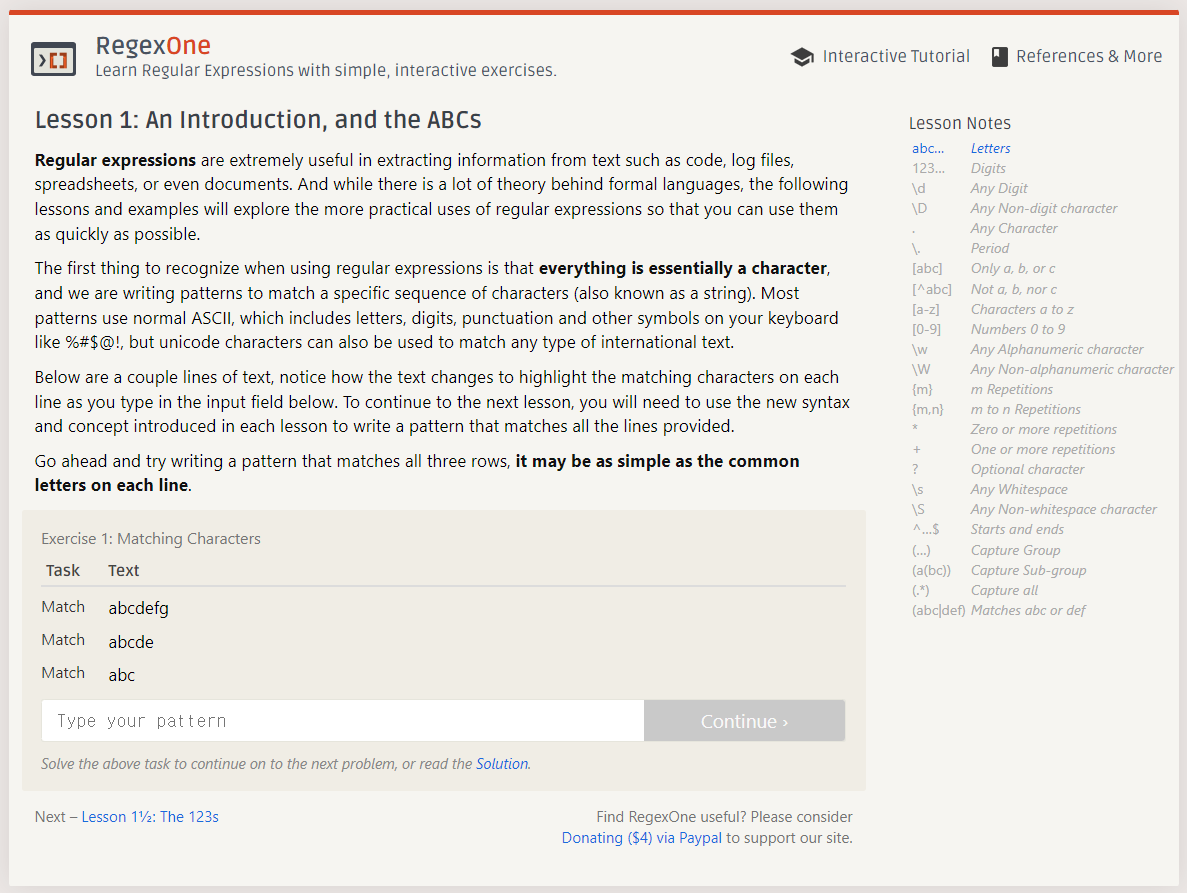
사이트에 처음 딱 들어가면 위와 같이 exercise 문제와 설명이 나와있고, 해당 문제가 어떤 표현식을 연습할 수 있는지 우측에 파란 글씨로 표시해준다.
또한 입력창 하단에 Solution도 나와있어 답을 모를 경우 해답도 참고할 수 있다.
1번

1-2번


세 문자열 모두 123이 공통적으로 들어가 있으므로 \d\d\d 또는 123을 입력하면 된다.
그리고 사실 제한 조건이 없기 때문에 \d나 1 하나만 들어가 있어서 옳은 답임
2번


이번 단계 부터는 skip이라고 해서 제한해야할 문자열 조건도 포함되기 시작했다.
오른쪽에 보니까 . 가 아무 문자를 나타내며 실제 온점을 표현하기 위해서는 \. 으로 입력하면 된다고 한다.
문자열들의 공통점이 마지막에 점이 있고, 문자가 앞에 세 개씩 있는 것이므로 . . . \. 을 입력해주었더니 통과!
사실 온점만 있어도 (\.만 입력해도) 통과되긴 한다.
3번

이 글 맨 처음에 들었던 예시와 같은 문제이다.
뒷 부분이 an으로 모두 일치하므로 앞의 c,m,f만 통과되도록 [ ]괄호로 조건을 부여하면 된다.
4번


[^a] 를 하면 Not a라는 의미이다.
따라서 bog의 b를 제한하기 위해 [^b]og 로 입력해줌
문제 의도와는 다르지만 3번 문제처럼 [h, d]로 제한해줘도 통과된다.
5번
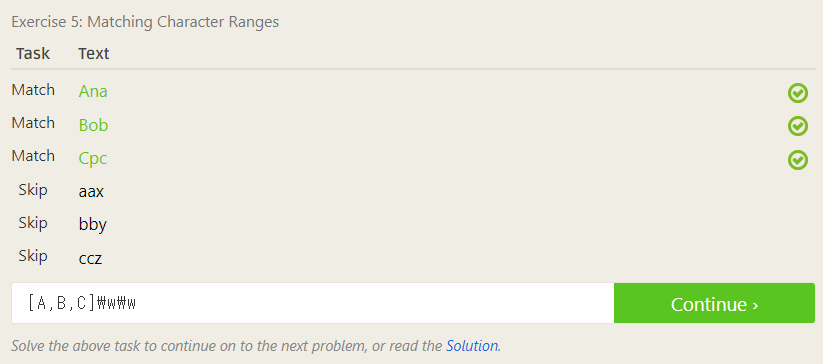

문자열들의 공통점으로는 모두 세 글자로 이루어져 있고, match와 skip의 차이로는 각각 같은 단어인데 대소문자만 달라서 [ ] 괄호로 제한해야 한다는 점이었다.
우측 레슨 노트에 보니 \w은 아무 알파벳 문자, \W은 아무 비알파벳 문자를 의미한다고 하므로 [A, B, C]\w\w로 입력했더니 통과되었다.
참고로 . 도 아무 문자를 의미하기 때문에 [A, B, C] . .도 통과된다.
6번


문자열에 반복된 z의 등장이 눈에 띄는데, 레슨 노트를 보니 {m}는 m번 반복 지정, {m,n}하면 m~n 번 반복을 지정할 수 있다고 한다. 현재 통과 문자열은 3번과 5번 반복되고 있으므로 waz{3,5}up 으로 입력해주니 통과!
7번



*은 0 이상의 반복, + 은 1번 이상의 반복을 의미한다고 한다.
현재 모든 문자열이 a로 시작하고 있지만 match 문자열들은 a가 연속으로 두 번 이상 나오고 있으므로, 제한 문자열인 a를 피하기 위해서는 1이상의 반복을 나타내는 +문자를 사용하여 aa+로 시작해준다. 사실 이렇게만 해도 통과이긴 한데, 문자열 전체를 맞추기 위해서 b*c+ 까지 해주면 완벽하게 적용이 되게 된다.
추가로 앞서 6번에서 사용했던 {} 반복문을 사용하여 a{2,4}b{0,4}c{1,2} 로 입력해도 통과된다!
8번
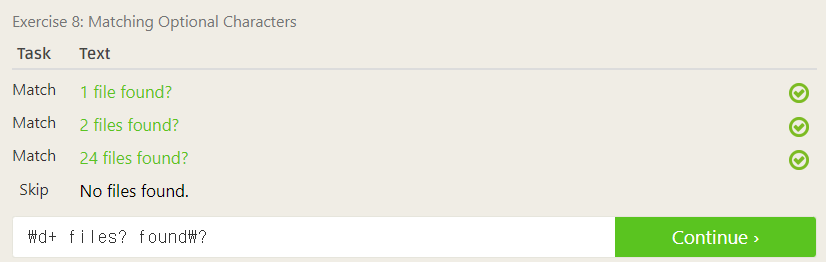

특정 문자 뒤에 물음표 문자 ? 를 붙이면 해당 문자를 optional로 처리할 수 있다고 한다.
문제의 match 문자열들에서 file과 files가 혼용이 되어있는 것을 볼 수 있는데, 이 때 s를 적절히 처리하기 위해 바로 뒤에 물음표 문자를 입력해주어 optional로 처리해준다. 따라서 앞의 숫자와 뒤의 문자열을 더한 \d+ files? found\?를 입력해주면 통과된다.
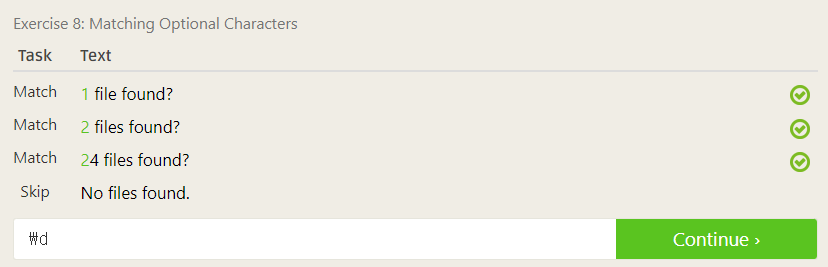
그러나 이는 match 문자열을 완전히 적용할 수 있는 방법이고, 간단하게 하려면 두 번째 사진처럼 그냥 앞에 숫자 \d 만 입력하던지 마지막 물음표인 \?만 입력해줘도 충분히 통과된다!
9번
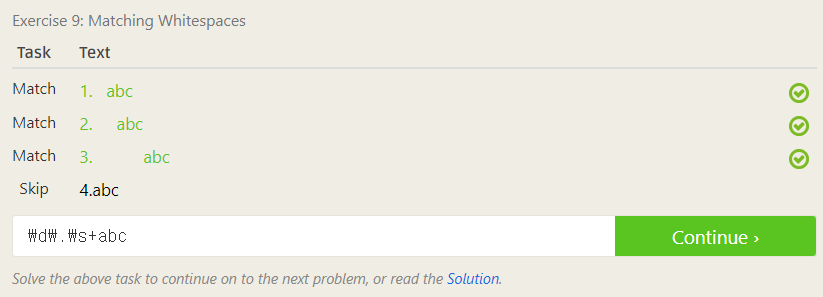

\s은 공백문자, \S은 비공백문자를 의미한다고 한다.
skip 문자열과의 차이점이 바로 이 공백이고, match 문자열들 간에 공백 문자 개수 차이가 존재하므로 \s+로 입력해주면 공백이 하나 이상인 문자열만 자동으로 통과될 것이다.
여기에 앞뒤로 필요한 문자들까지 갖춰주면 완벽하게 통과 가능!
10번
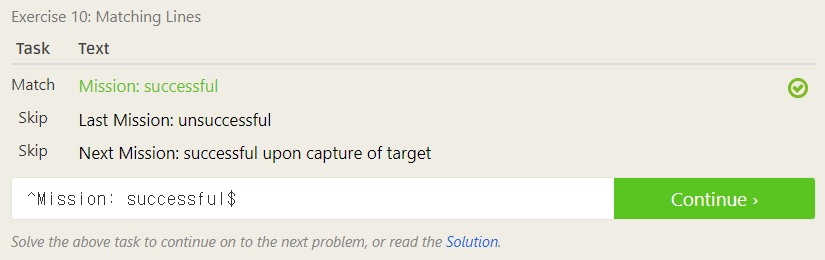

정규표현식에서 ^은 줄의 시작, $은 줄의 끝을 의미한다.
이를 이용해서 위와 같이 앞뒤로 ^와 $을 넣어주면 간단하게 통과
11번

앞의 문제까지는 match하는게 task였다면, 이번 문제는 capture하는 것이 목표이다.
앞 문제에서 사용했던 ^와 $문자를 사용하여 앞뒤로 넣어주고 뒷부분 확장자가 \.pdf로 끝나도록 지정해준다.
그 뒤 문제에서 사용하라고 하는 capture () 기호를 사용하여 아무 문자( . )를 1개 이상 포함하는 조건을 붙여서 이 괄호 안의 이름을 추출할 수 있도록 하면 위와 같이 정상적으로 capture가 완료된것을 볼 수 있다.
12번

그리고 괄호를 이렇게 겹쳐서 사용하면 sub-group capture 도 가능하다.
지금 캡쳐 대상으로 전체 문자열과 뒷부분의 숫자도 같이 캡쳐하라고 지시하고 있기 때문에 일단 앞부분을 아무 문자인 (.)+과 공백문자(\s)를 붙여서 삽입한 뒤 서브 그룹 괄호를 열어서 숫자인 \d를 넣어서 성공했다.
13번



(.*)을 입력하면 전체를 캡쳐할 수 있다고 한다.
현재 각 문자열에서 중간의 x를 기준으로 양옆의 숫자를 캡쳐해야 하기 때문에 괄호를 두 번 양쪽에 넣어주고 (.*)를 입력해주면 통과된다. 또한 숫자이므로 \d+를 해줘도 마찬가지 기능!
14번


레슨 노트에서 알려줬듯이 (abc|def) 하면 abc 또는 def를 맞출 수 있다고 한다.
이를 적용하여 cats 또는 dogs를 맞추도록 입력하면 통과!
'Linux' 카테고리의 다른 글
| [Rocky Linux] 웹 서버 LAPM 구축하는 방법 (1) | 2024.11.05 |
|---|---|
| [Rocky Linux] SSH/RDP 서버 설정 및 원격 접속하는 방법 (0) | 2024.11.05 |
| [Linux] 텍스트 편집기 vi(vim) 사용 방법 & 명령어 모음 (0) | 2024.09.18 |
| [Linux] VMware Workstation Pro 17 설치 방법 (Broadcom ver.) (0) | 2024.09.04 |
| [Ubuntu] gcc 설치 오류 해결 방법 : sudo apt-get install gcc (0) | 2024.09.01 |