
공공데이터포털에서 XML 페이지 열람하는 방법은 앞선 포스팅을 참고!
https://sallysooo.tistory.com/2
1-1. 분석에 필요한 패키지
- '웹 크롤링' 또는 '웹 스크렙핑'은 웹에서 원하는 정보를 수집하는 작업
- API를 이용한 데이터 수집도 웹 크롤링의 한 가지 방법
1) requeset package를 통해 원하는 웹페이지 불러오기
2) BeautifulSoup 패키지로 파싱하여 웹페이지를 파이썬 객체로 변환, HTML 테그 정보 등을 활용하여 원하는 데이터 추출
beautifulsoup 패키지가 없다면 cmd 창에 다음 코드를 입력하여 설치할 수 있다.
pip install beautifulsoup4
pip install lxml
1-2. 오픈 API를 통한 아파트매매실거래가 입수
from urllib.request import urlopen # request package
from bs4 import BeautifulSoup # BeautifulSoup
import pandas as pd # pandas
month = 202106 # 2021년 6월
gu_code = 11650 # 서초구 구코드
service_key = "" # 서비스키 입력
# 오픈 API url 형태
url=f'http://openapi.molit.go.kr:8081/OpenAPI_ToolInstallPackage/service/rest/RTMSOBJSvc/'\
f'getRTMSDataSvcAptTrade?LAWD_CD={gu_code}&DEAL_YMD={month}&'\
f'serviceKey={service_key}'
result = urlopen(url) #url 오픈
house = BeautifulSoup(result, 'lxml-xml') #url을 xml 방식으로 취합
te = house.find_all('item') #item 항목만 추출하여 te로 저장
print(te[0])
앞서 xml 페이지를 열람할 때 입력했던 url을 가져와서 요청변수 3개를 위 형태처럼 변수로 대체한다.
(링크가 길기 때문에 f 스트링을 활용해서 중괄호 부분에 각 변수가 들어가도록 함)
month 변수에는 원하는 데이터의 날짜를, gu_code에는 원하는 데이터의 법정동 코드를, service_key에는 인증키를 넣은 뒤 코드를 실행하면 된다.
print 함수로 te[0]를 출력해보면 다음과 같다. (VSC 이용)

beautifulsoup를 통해 읽은 주택실거래가 데이터는 item이라는 tag 형태로 저장되어 있는 것을 볼 수 있다.
이를 파이썬을 이용해 데이터를 리스트 형태로 저장해보자.
for 반복문을 이용해 <item> tag 안에 있는 데이터에 대한 변수명을 지정하고, 이를 리스트 형태의 데이터로 변환한다.
data = [] #빈 리스트 생성
for i in range(len(te)): #te 개수만큼 데이터 추출 반복
price = te[i].거래금액.string.strip()
built_yr = te[i].건축년도.string.strip()
dong_name = te[i].법정동.string.strip()
apt_name = te[i].아파트.string.strip()
size = te[i].전용면적.string.strip()
gu_code = te[i].지역코드.string.strip()
total = [month, price, built_yr, dong_name, apt_name, size, gu_code] #추출 데이터를 리스트로 취합
data.append(total) # total을 data 리스트에 넣기
print(data[:5]) # 5개 출력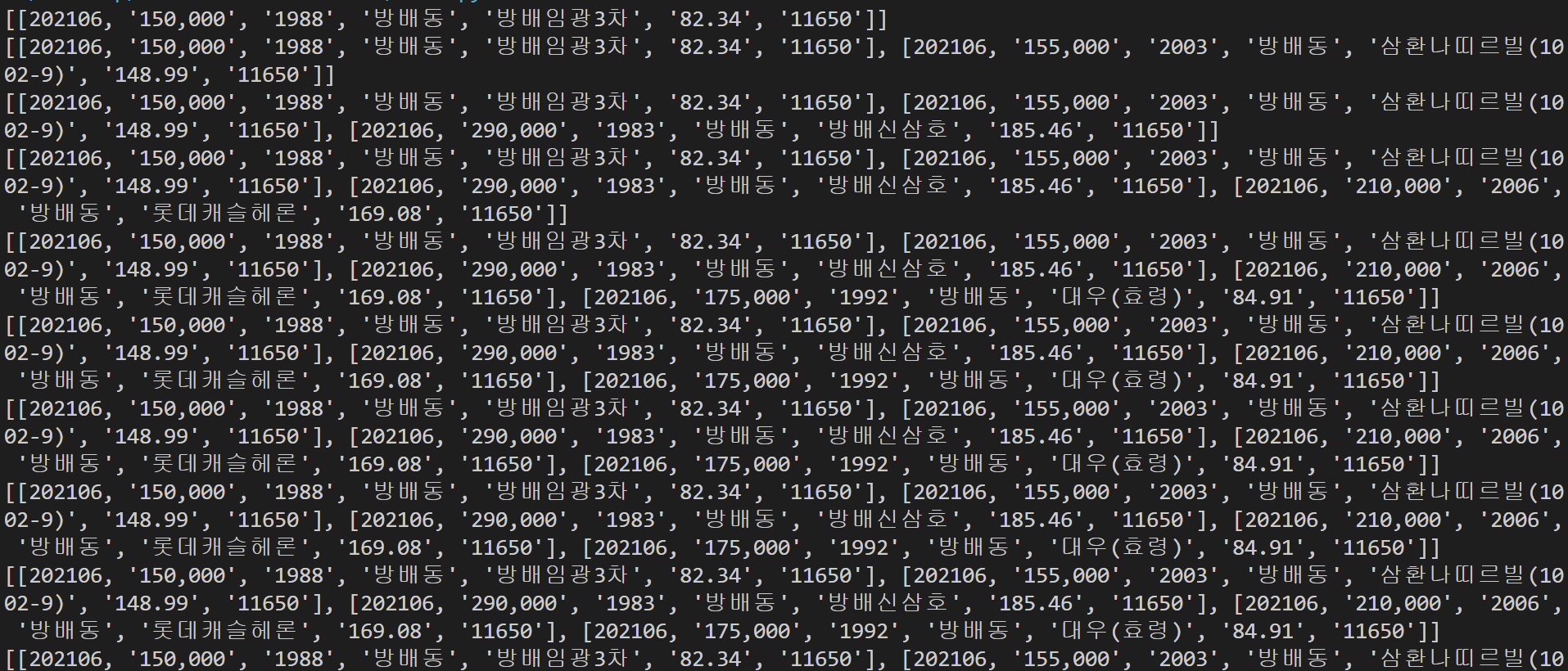
데이터를 목적에 맞게 가공하기 위해 리스트 형태의 데이터를 판다스의 데이터프레임으로 바꾼다.
df = pd.DataFrame(data, columns=["month", "price", "built_yr", "dong_name", "apt_name", "size", "gu_code"])
print(df)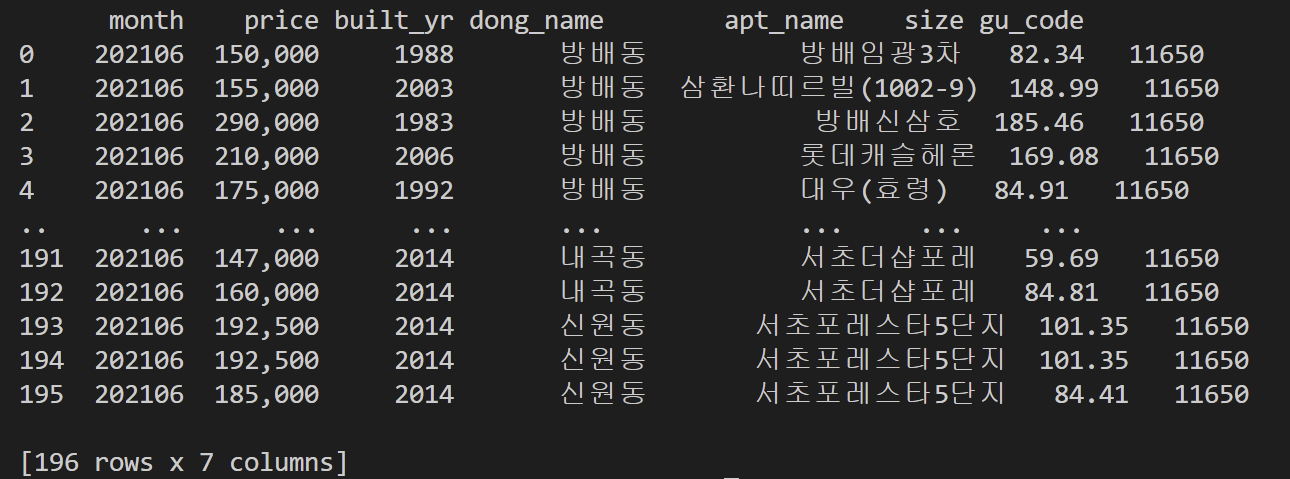
향후 이 정렬된 데이터셋을 사용하기 위해 csv 파일로 저장하기
# 코딩이 저장되는 디렉토리에 df가 csv 파일로 저장
df.to_csv('house_price.csv')
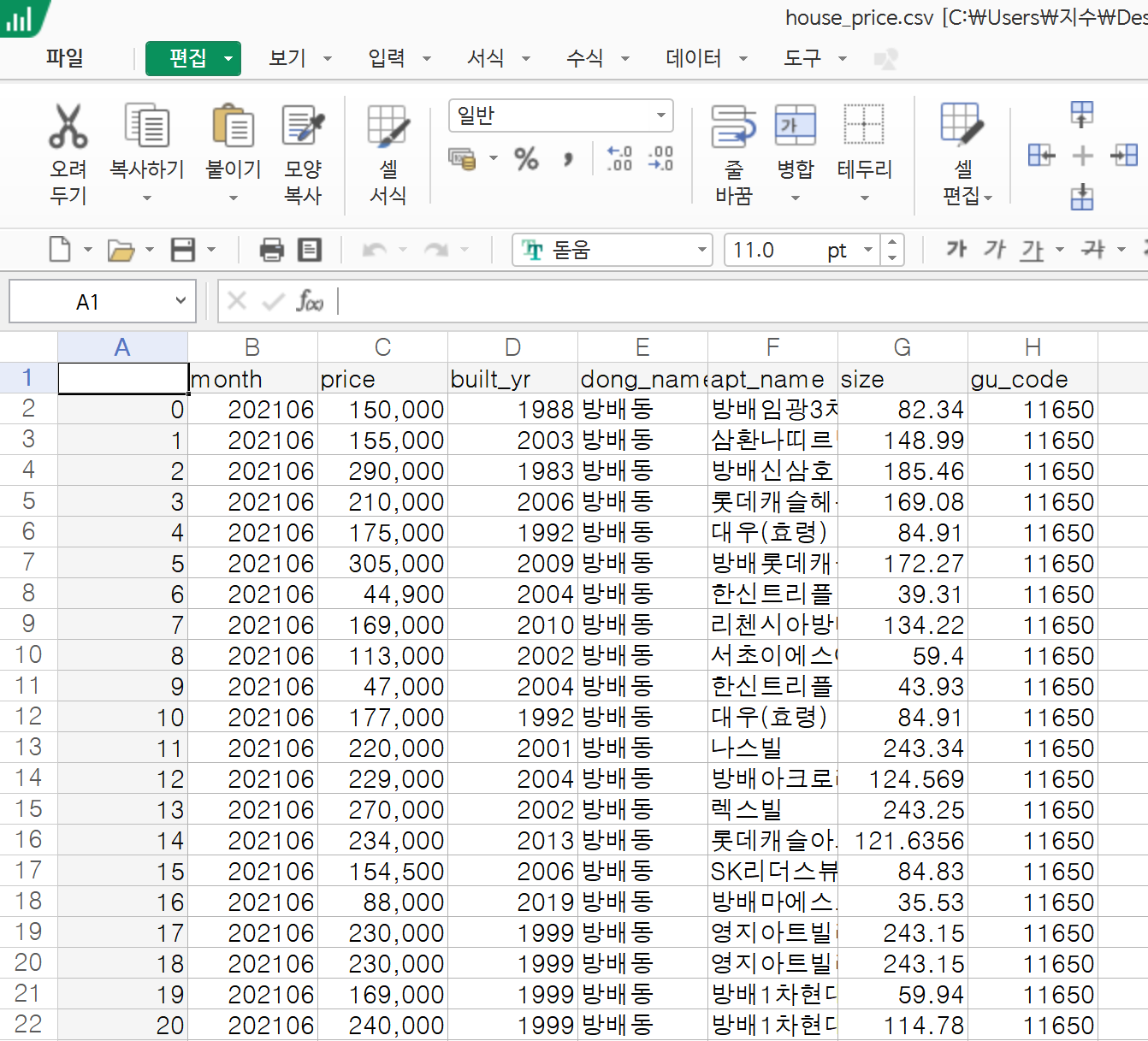
그럼 위와 같이 해당 디렉토리에 csv 파일이 자동으로 저장되고, 열어보면 표 형태로 정리된 것을 볼 수 있다.
이제 만들어진 csv 형식 데이터를 대상으로 아파트매매 실거래가 분석을 해보자.
2. 아파트매매 실거래가 분석
1) 판다스로 csv 파일 불러오기
import pandas as pd
#csv 파일을 데이터프레임 형식으로 읽고 이름을 df로 지정
df=pd.read_csv('house_price.csv')
print(df)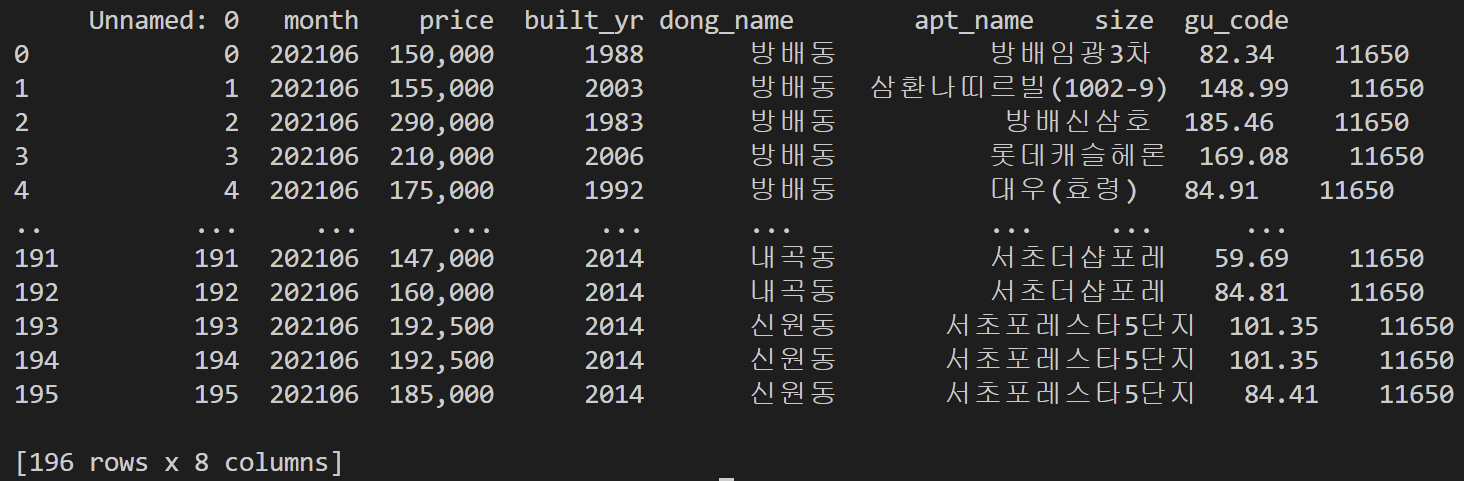
2) 열 이름 확인 (column 명)
df.columns #df의 칼럼 이름 출력
출력해보니 첫 번째 열로 인덱스 열까지 같이 들어간 듯 하니 불필요한 unnamed 열을 삭제해야할 것 같다.
3) 행 기준으로 데이터 추출
df = df.drop('Unnamed: 0', axis=1) #불필요한 열 삭제
print(df[2:4]) # 행 추출
참고로 판다스에서는 행이 axis=0, 열이 axis=1이고 넘파이는 반대임을 주의!

3) 열 기준으로 데이터 추출
df[['price','size']] # 열 추출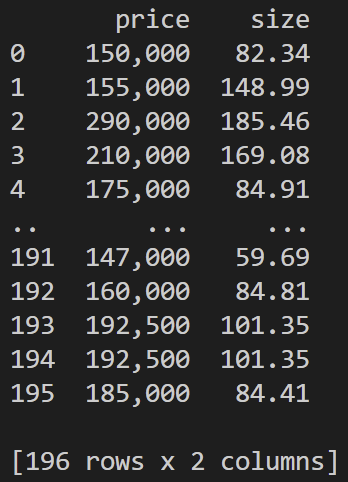
4) 행과 열의 "위치"를 기반으로 데이터 추출 -> iloc
df.iloc[2:5, 0:2]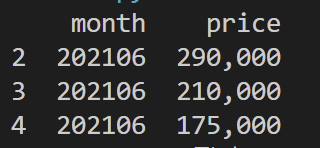
5) 행의 "인덱스"와 열의 "칼럼 이름"을 기반으로 데이터 추출 -> loc
df.loc[df.index[2:5],['month','price']]
6) 칼럼의 형식 확인
df.info()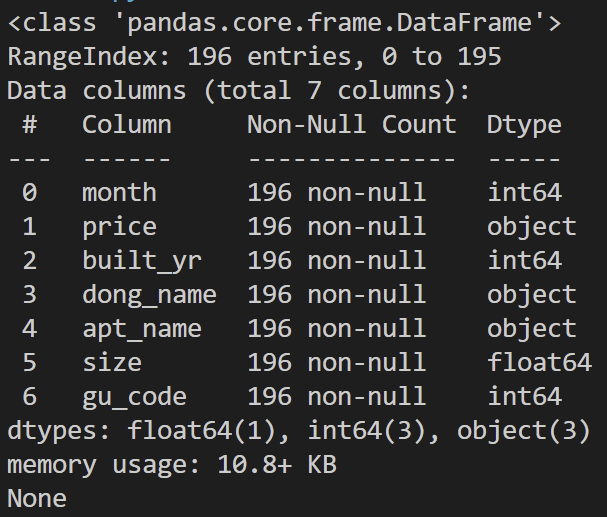
보아하니 price가 문자(object) 형식으로 저장되어 있는데, 이는 160,000 과 같은 형태로 반점이 들어가 있기 때문이다.
따라서 이를 활용해 수 계산할 수 있도록 정수로 바꿔줘야 함을 알 수 있다.
7) 정수 변환
#price에서 '.'을 제거하고 정수로 변환
df['price']=df['price'].str.replace(',', '').astype(int)
print(df.head())
위와 같이 price열에서 콤마가 제거되어있는 것을 볼 수 있고, df.info()를 해보면 int로 변환되어서 나온다.
8) 평당가격 변수 생성
아파트의 평당가격을 나타내는 변수를 생성한다.
이를 위해 아파트 크기를 평으로 전환시켜주는 변수를 생성한다.
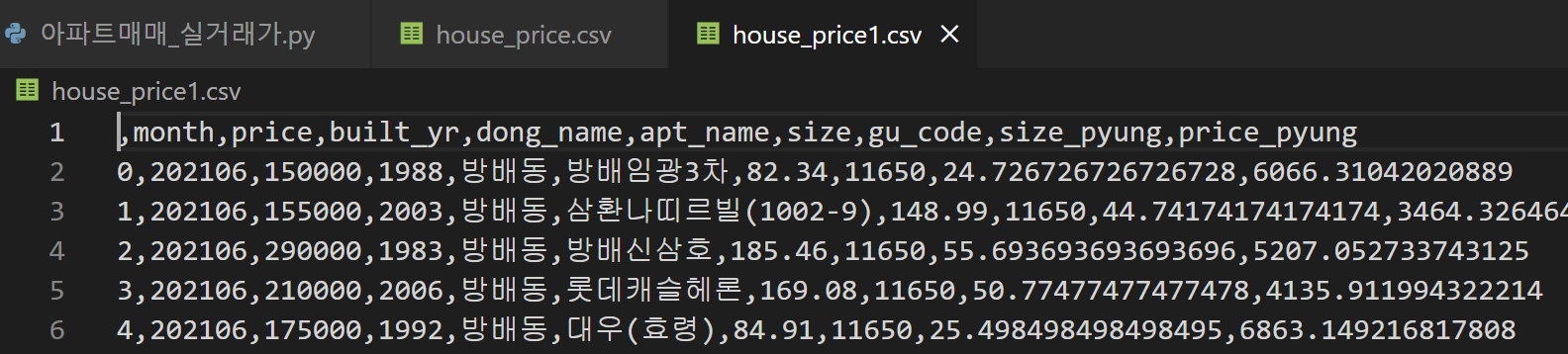
df['size_pyung'] = df['size']/3.33 # 주택 크기를 평으로 전환
df['price_pyung'] = df['price']/df['size_pyung'] # 평당 주택 가격을 나타내는 변수 생성
print(df.head())
3. 기술 통계량
1) 데이터에 대한 각종 정보 추출
df.describe()
데이터 개수, 평균, 표준편차, 중간값, 최소값, 최대값, 25 percentile, 75percentile 정보 출력
2) price에 대한 평균과 표준편차
price_mean = df['price'].mean()
price_std = df['price'].std()
print(price_mean)
print(price_std)
3) csv 파일로 저장
df.to_csv('house_price1.csv') # 판다스 데이터프레임 형식을 csv 파일로 저장
'Data Science' 카테고리의 다른 글
| 엑셀 csv 파일 한글 깨짐 오류 해결 방법 (0) | 2024.07.30 |
|---|---|
| 공공데이터포털 가입 및 인증키 받기 (0) | 2023.12.21 |