
1. Polars(폴라스)란?
Rust로 만들어져 Python, JavaScript 등에서 사용할 수 있는 고성능 데이터프레임 라이브러리로, Pandas의 강력한 대안으로 떠오르며 특히 대용량 데이터 처리에서 뛰어난 속도를 자랑한다.
또한 멀티코어 CPU를 활용한 병렬처리, 벡터화된 연산, 지연 평가(lazy evaluation) 및 효율적인 메모리 관리(zero-copy 데이터 공유)를 통해 대규모 데이터를 빠르고 효율적으로 분석하는 데 특화되어 있다.
- Rust 기반 + 병렬 처리 기본 : 연산을 내부적으로 멀티스레드로 잘 돌림
- Arrow 컬럼형 memory format : column 단위 연산(filter/join/etc.)이 유리
- Lazy API : 여러 연산을 계획으로 묶어서 최적화한 뒤 한 번에 실행 (query optimizer 같은 느낌)
위 특징들로 인해 큰 파일(parquet/csv)에서 scan_*(lazy 로딩) + 필요한 컬럼만 select + filter걸기 3가지만 해도 pandas와 대비해서 확연한 성능 차이를 체감할 수 있다.
2. Polars 기초 활용법
1) DataFrame (eager)
- pandas처럼 지금 바로 실행
- 작은/중간 데이터, 디버깅, 빠른 확인에 편리함
2) LazyFrame (lazy)
- scan_csv, scan_parquet 등으로 시작
- .select().filter().group_by()를 연결만 해두고, 마지막에 .collect()할 때만 실행하는 방식이므로 lazy라고 하는것!
polars의 각종 연산들은 대부분 pandas와 크게 다르지는 않지만, 그래도 미묘하게 다른 부분이 꽤 있으니 한 번 살펴보자.
1. 설치 및 기본 세팅
pip install polars
# conda 환경일 경우
conda install polarsimport polars as pl
2. 데이터 로드(읽기)
# csv file
df = pl.read_csv("data.csv") # eager
lf = pl.scan_csv("data.csv") # lazy
# 대용량 parquet file
df = pl.read_parquet("part-00000.parquet")
lf = pl.scan_parquet("*.parquet") # 여러 파일
# 필요한 column만 먼저 가져오기
lf = pl.scan_parquet("*.parquet").select(["col1", "col2", "col3"])
df = lf.collect()
3. 데이터 확인
- pandas의 메소드들과 크게 다르지 않다!
df.head(5)
df.tail(5)
df.shape
df.columns
df.schema # 컬럼 dtype
df.describe() # 요약 통계
df.null_count() # 결측치 개수
4. 컬럼 선택/추가/변환 - 표현식(expression)
- polars는 문자열로 컬럼을 찍고 끝이 아니라, pl.col(...)로 컬럼 표현식을 만들어서 조합하는 스타일이다.
df.select([
pl.col("a"),
pl.col("b").alias("b2"),
])# with_columns (컬럼 추가/변환)
df = df.with_columns([
(pl.col("x") * 2).alias("x2"),
(pl.col("y") / pl.col("z")).alias("ratio"),
])# dtype 변환
df = df.with_columns([
pl.col("id").cast(pl.Int64),
pl.col("ts").str.strptime(pl.Datetime, "%Y-%m-%d %H:%M:%S"),
])
5. 필터링 (조건)
df.filter(pl.col("price") > 1000)
df.filter(
(pl.col("brand") == "BMW") & (pl.col("year") >= 2018)
)
자주 쓰는 조건 util들:
is_null(). is_not_null()
is_in([...])
str.contains("..."), str.starts_with(...)
6. 정렬, 중복 제거, 결측치 처리
df.sort("price", descending=True)
df.unique(subset=["id"]) # 중복 제거
df.drop_nulls() # null 있는 행 제거
df.fill_null(0) # null 채우기
7. Groupby 집계
df.group_by("brand").agg([
pl.len().alias("n"),
pl.col("price").mean().alias("avg_price"),
pl.col("price").median().alias("med_price"),
])
8. Join / concat
df3 = df1.join(df2, on="id", how="left") # inner/left/right/full
df_all = pl.concat([df_a, df_b], how="vertical")
9. 문자열/날짜 처리
# 문자열
df = df.with_columns([
pl.col("name").str.to_lowercase().alias("name_l"),
pl.col("text").str.contains("error").alias("has_error"),
])
# 날짜/시간
df = df.with_columns([
pl.col("ts").dt.date().alias("date"),
pl.col("ts").dt.hour().alias("hour"),
])
3. Polars로 대용량 최적화하는 실전 example
앞서 간단하게 데이터 분석을 위한 사용법을 살펴보았고,
다음으로 이 글의 본론인 Lazy로 대용량 데이터를 처리하는 방법에 대해서 실제 예시 코드를 통해 살펴보자.
0) 준비 단계 : Parquet 전체 scan handle 만들기 (LazyFrame)
import polars as pl
pl.Config.set_engine_affinity(engine="streaming")
import polars as pl
DATA_DIR = "src/data/window_parquet"
PATH = f"{DATA_DIR}/part-*.parquet"
lf = pl.scan_parquet(PATH) # LazyFrame
1) 간단한 데이터 분석
# 전체 row 수 출력
n_rows = lf.select(pl.len().alias("n_rows")).collect()
print(n_rows)
# pcap_file별 row 수
by_pcap = (
lf.group_by("pcap_file")
.agg(pl.len().alias("n_windows"))
.sort("n_windows", descending=True)
.collect()
)
print(by_pcap.head(20))
whole_week.pcap이라는 파일 하나만 사용했기 때문에 이 하나에 대해서만 출력된다.
# ip_version / proto 분포 확인
dist = (
lf.group_by(["ip_version", "proto"])
.agg(pl.len().alias("n_windows"))
.sort("n_windows", descending=True)
.collect()
)
print(dist)
2. 윈도우 단위 용량 및 길이 분포 확인하기
# 윈도우당 총 bytes (rawlen0+1+2)
win_size = (
lf.with_columns(
(pl.col("rawlen0") + pl.col("rawlen1") + pl.col("rawlen2")).alias("win_rawlen")
)
.select([
pl.col("win_rawlen").mean().alias("mean"),
pl.col("win_rawlen").median().alias("median"),
pl.col("win_rawlen").quantile(0.90).alias("p90"),
pl.col("win_rawlen").quantile(0.99).alias("p99"),
pl.col("win_rawlen").max().alias("max"),
])
.collect()
)
print(win_size)
3. 데이터가 정상적으로 생성됐는지 체크
# rawlen = hlen + plen 체크
bad_len = (
lf.filter(
(pl.col("rawlen0") != pl.col("hlen0") + pl.col("plen0")) |
(pl.col("rawlen1") != pl.col("hlen1") + pl.col("plen1")) |
(pl.col("rawlen2") != pl.col("hlen2") + pl.col("plen2"))
)
.select(["stream_id","w_idx","rawlen0","hlen0","plen0","rawlen1","hlen1","plen1","rawlen2","hlen2","plen2"])
.limit(20)
.collect()
)
print(bad_len)
# 한 윈도우 안에서 pktno/ts가 증가하는지 (순서 깨짐 여부)
bad_order = (
lf.filter(
(pl.col("pktno0") >= pl.col("pktno1")) | (pl.col("pktno1") >= pl.col("pktno2")) |
(pl.col("ts0") > pl.col("ts1")) | (pl.col("ts1") > pl.col("ts2"))
)
.select(["stream_id","w_idx","pktno0","pktno1","pktno2","ts0","ts1","ts2"])
.limit(20)
.collect()
)
print(bad_order)
4. 어떤 stream이 압도적으로 많은지 비율 확인
top_streams = (
lf.group_by("stream_id")
.agg(pl.len().alias("n_windows"))
.sort("n_windows", descending=True)
.limit(20)
.collect()
)
print(top_streams)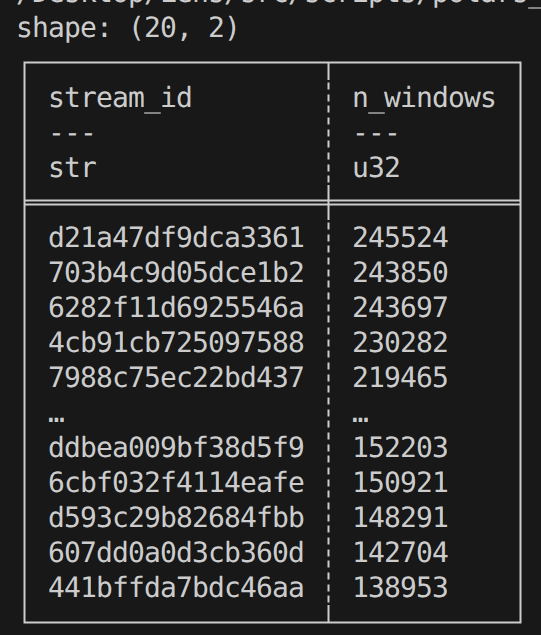
# stream 길이 (패킷 수)를 w_idx 최댓값으로 보기
stream_span = (
lf.group_by("stream_id")
.agg([
pl.max("w_idx").alias("max_w_idx"),
pl.min("w_idx").alias("min_w_idx"),
pl.len().alias("n_windows")
])
.sort("n_windows", descending=True)
.limit(20)
.collect()
)
print(stream_span)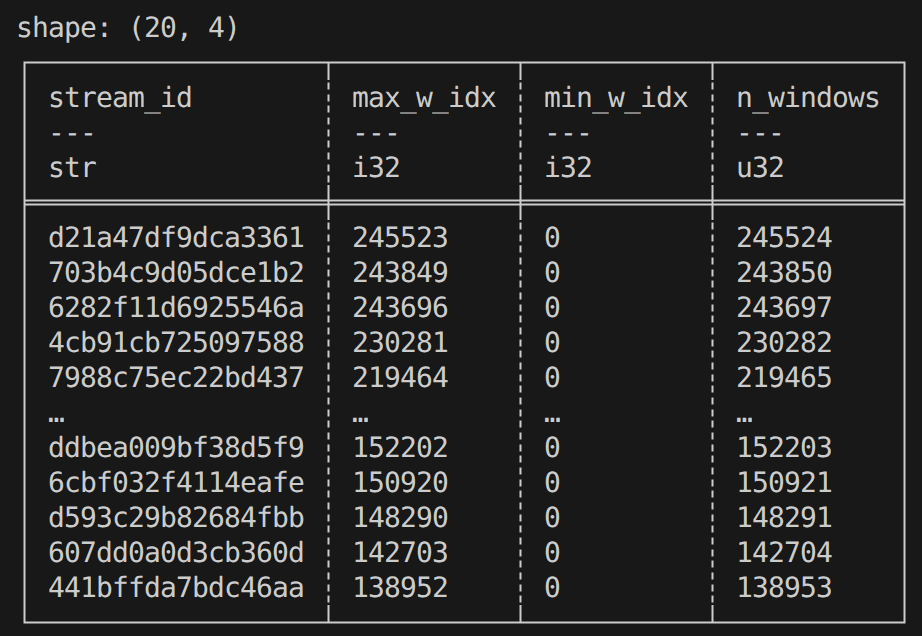
5. random sample 뽑기 (bytes 확인)
# 작은 샘플만 eager로 가져오기
sample = (
lf.select([
"stream_id","w_idx","pcap_file",
"ts0","dir0","hlen0","plen0","rawlen0","pktno0",
"header0","payload0",
])
.collect()
.sample(n=5, seed=42)
)
print(sample)
preview = sample.with_columns([
pl.col("header0").map_elements(lambda b: b[:32].hex(), return_dtype=pl.Utf8).alias("header0_hex32"),
pl.col("payload0").map_elements(lambda b: b[:32].hex(), return_dtype=pl.Utf8).alias("payload0_hex32"),
]).select(["stream_id","w_idx","hlen0","plen0","header0_hex32","payload0_hex32"])
print(preview)
'Python' 카테고리의 다른 글
| [Python] 벡터화(Vectorization) 연산이란? | PyTorch, NumPy vectorize 개념 설명 및 예제 코드 (0) | 2025.12.20 |
|---|---|
| [Python] DFS BFS 개념 정리 | 깊이 우선 탐색과 너비 우선 탐색 설명 및 예제 코드 (6) | 2025.08.04 |
| [Python] 구현 (Implementation) : 이론 및 예제 문제 풀이 (6) | 2025.07.27 |
| [프로그래머스/Python] 42885 : 구명보트 - 그리디 알고리즘 (3) | 2025.07.27 |
| [프로그래머스/Python] 12982 : 예산 - 그리디 알고리즘 (2) | 2025.07.26 |