
KNIME 5.2.5 기준으로 작성하였음.
1. Overview of KNIME
일단 KNIME을 설치하고 들어가보면 다음과 같은 화면이 뜨는데, 각각의 역할에 대해서 간단히 알아보자.

1. KNIME explorer
- workflow file들을 포함하고 있는 카테고리별 workflowgroup files 생성
2. Node Repository
- workflow editor에서 사용할 수 있는 노드 저장소
3. Workflow Coach
- 현재 선택한 노드 다음에 어떤 노드가 가장 많이 사용되는지 제안해주는 역할 (% 확률로 recommend)
4. Workflow Editor
- Node port : input port, output port
ex) file reader, joiner
- Node status
Red (비활성화) / Yellow (노드 설정됨 & 비실행 상태) / Green (노드가 성공적으로 실행된 상태)
- Connection between nodes
5. Node Description
- 노드 도움말 : 선택한 노드의 역할, 옵션 및 포트에 대한 설명, 노드가 포함된 확장 기능 설명
6. Outline
- Workflow Editor의 축소판 화면
7. Console
- 실행된 워크플로우의 상태나 실행 중 발생한 경고 메시지 출력
2. Data Collection

- node : Excel reader
- 엑셀 파일 읽기 : xlsx

- node : file reader
- 형식 파일 가져오기 : csv file, text file
- 문자형 : I(integer), D(Double), S(String)
** delimeter : 콤마 같은 구분자

- node : csv writer
- 엑셀 파일을 읽어서 csv 형식 파일로 작성해주는 노드 (확장자 변경)
방법은 다음과 같다.


이 때 fail 대신 overwrite로 선택하는 것을 추천함

- node : excel writer
- csv 파일을 엑셀로 변환하여 내보내기 (.xls, .xlsx)
3. Data Preprocessing
<데이터 조인(joiner)>
- 두 개의 테이블에서 지정한 키 변수를 기준으로 조인 => 새로운 테이블 생성
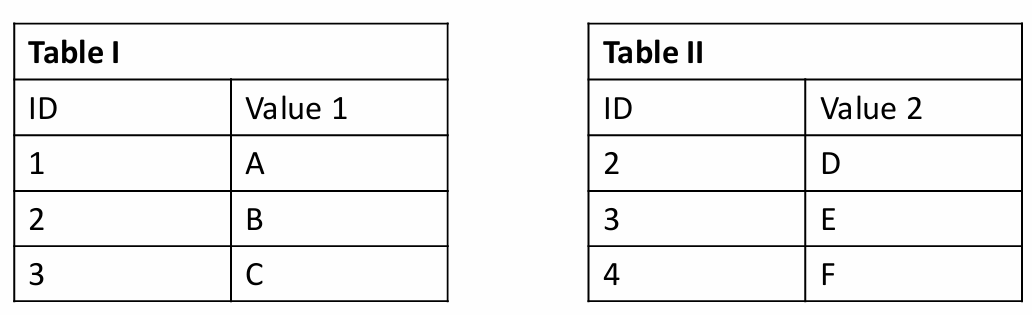
1. Inner join : 두 테이블에서 키 변수 (ID) 값이 동일한 행만 조인
2. Left Outer join : 첫 번째 테이블의 키 변수와 일치하는 값을 갖는 두 번째 테이블의 행을 붙여줌
- 일치하지 않는 키 변수에 해당하는 값은 결측치 처리.
3. Full Outer join : 두 테이블의 키 변수가 일치하는 행은 두 테이블의 값으로 붙여줌
- 일치하지 않는 행의 값은 결측값


<테이블 읽고 쓰기>
- Table writer : joiner를 통해 출력된 데이터를 .table 파일을 생성하여 로컬 컴퓨터에 저장
- Table reader : .table 파일을 다시 가져오는 노드
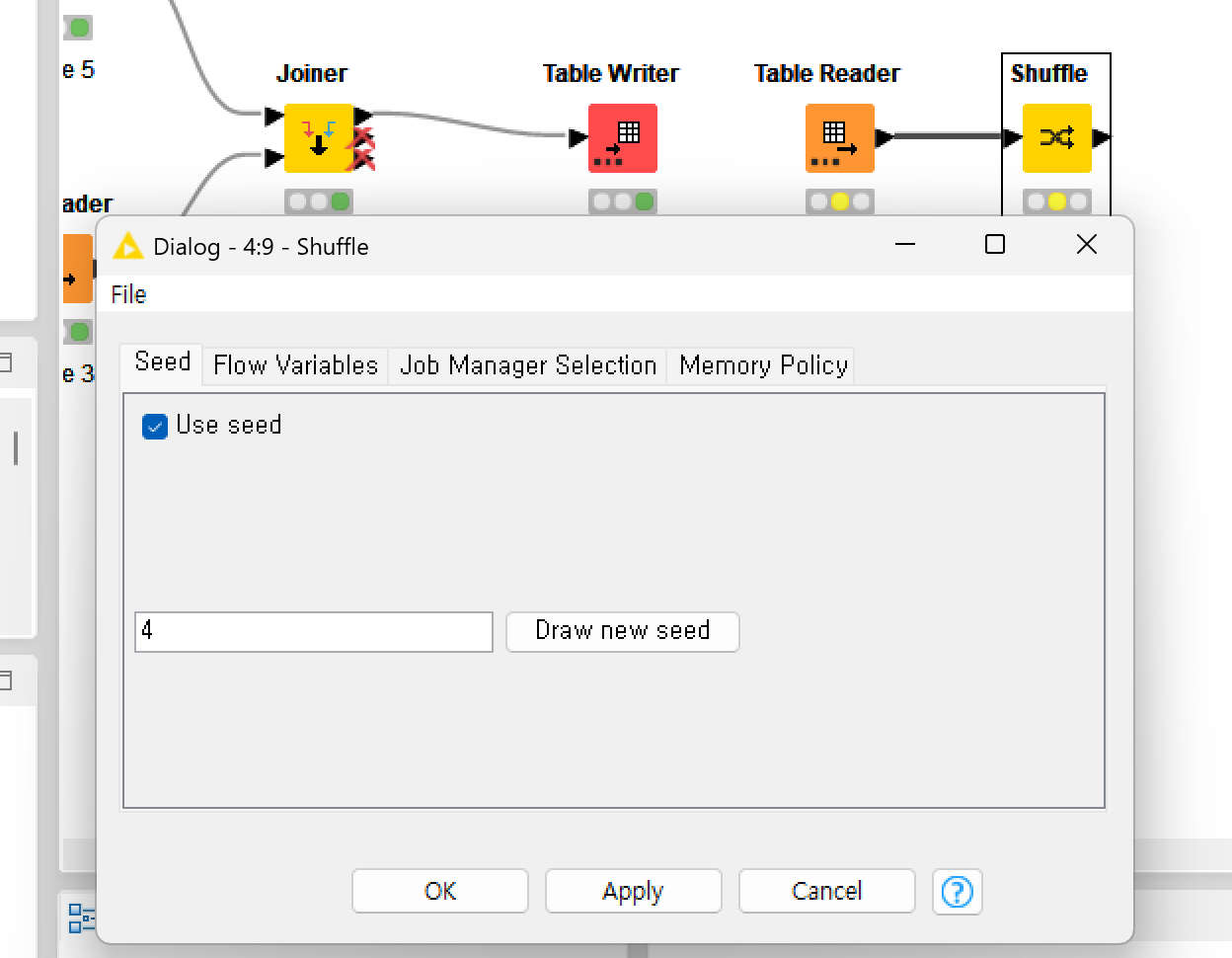
<데이터 셔플(shuffle)>
- 임의의 순서로 행을 재배열 + seed 사용해야 execute 할 때마다 순서 변경됨
<데이터 연결(concatenate)>
- 두 개의 테이블을 결합하여 새로운 테이블 생성


<groupBy 노드 : 그룹화>




mean / mode / unique count를 주로 사용함!
<피벗테이블 생성(pivot)>
- 그룹 변수, 피벗 변수, 집계 변수를 선택하여 피벗 테이블을 출력

Q. 출력 테이블 종류?
- pivot table (port0) : 그룹 변수와 피벗 변수 기반 집계 반환
- Group totals (port1) : 그룹 변수 기반 집계 반환
- pivot totals (port2) : 피벗 변수의 고유값 기반 집계 반환
Q. 옵션?
- Ignore missing values : 피벗 변수의 결측값을 무시
- Append overall total : pivot totals 출력 테이블에 가장 마지막 열에 추가적으로 전체에 대한 집계 정보 표시
- column name & aggregation name
- sort lexicographically : 피벗 변수의 값을 기준으로 오름차순으로 변수 나열
- 값이 결측치인 경우, 그룹 변수 다음으로 맨 앞에 변수 배치
Q. 피벗 해제하기(Unpivot)?
- 테이블에서 변수를 행의 값으로 변환
- value columns : 값으로 변환시킬 변수 선택
- retained columns : 기존 변수 그대로 출력할 변수 선택
- 사실상 vice versa로 컬럼 이름 자체가 하나의 요소가 되어 각 행에 들어가게됨

<데이터 정렬 (sorter)>
- 변수나 row ID를 오름차순 or 내림차순으로 정렬


<행 필터(row filter)>
- 조건을 만족하는 행을 찾아 데이터를 추출
<열 필터(Column filter)>
- 선택한 변수만 추출하여 테이블을 출력
- wildcard, regex, type 등으로 컬럼을 골라서 선택할 수 있는데, 주로 편하게 manual을 사용
<데이터 분할(partitioning)>
- 입력 데이터를 2개의 출력 데이터로 분할 (train/test split)
- linear sampling : 첫 번째와 마지막 행을 항상 포함하면서 일정 간격으로 선택
- draw randomly : 무작위로 선택
<행 샘플링(row sampling)>
- 행의 개수 또는 비율을 설정하여 샘플링
<테이블 열을 매개변수로 사용하기(Table Column to Variable)>
- 테이블의 열을 매개변수로 변환
- 매개변수로 사용할 열을 지정한 후, 지정된 열의 모든 행의 값은 RowID를 이름으로 갖는 매개변수로 변환
<테이블 행을 매개변수로 사용하기(Table Row to Variable)>
- 테이블의 첫 행을 매개변수로 변환
- missing values : use defaults(기본값 대체) / omit(생략)
<매개변수 모으기(merge variable)>
- 여러 매개변수 포트를 하나의 매개변수 포트로 모아주는 노드
<열 분할(Cell splitter)>
- 셀 안에 있는 값을 "구분자"를 기준으로 잘라서 "새로운 변수" 생성
- column to split : select a column / remove input column

- list는 복제가 가능하지만, set은 복제 불가 (remove duplicates)
- missing value : cell은 null의 의미인 ? 가 들어가있음
- empty string cells : 아무것도 없음
<위치 기준 열 분할 (cell splitter by position)>
- 선택한 열을 지정한 위치를 기준으로 여러 개의 새로운 열로 분할
- split indices는 new column names의 수보다 항상 1개 적어야한다.
- 2개를 기준으로 분할하면3개의 그룹이 생성되는 원리이기 때문!


<column filter>
- 마지막에 이걸 거쳐주면 내가 변경한 column만 볼 수 있으므로 사용하는 것을 추천

<집합 열 생성(create collection column)>
- 기존의 변수를 결합하여 collection 형식의 변수를 생성


<열 결합(column combiner)>
- 변수들을 구분자를 사용하여 결합해서 새로운 변수 생성
- Quote character : delimeter와 동일한 문자가 셀 값에 있을 경우, 해당 셀 값에 인용 부호를 추가하여 결합
- replace delimeter by : 구분자와 동일한 문자가 셀 값에 있을 경우 대체하기


<수식 활용(math formula)>
- 수치형 변수에 대해서 수학 공식을 이용하여 계산
- 계산된 결과는 새 열로 추가 또는 기존 열을 대체

<문자열 치환(String replacer)>
- 문자형 또는 Date&Time 타입의 변수를 다른 문자로 대체
- replacement text : 대체할 문자를 설정
<문자열 수정(String Manipulation)>
- 함수를 사용하여 새로운 변수 생성
<결측값(Missing Value)>
- 데이터의 결측값을 처리
- default : 데이터 형식에 따라 결측값 일괄 처리
- column settings : 변수를 직접 선택하여 결측값 처리
<행 ID 설정(Row ID)>
- RowID를 수정 또는 대체하거나 변수로 추가
<열 이름 변경(Column Rename)>
- 변수의 이름 또는 타입을 변경
<날짜형 타입 변환(Legacy Date&Time to Date&Time)>
- 지역 설정 (time zones) 정보를 포함하는 새로운 타입의 Date&Time으로 변환
- 즉 기존의 date&time 포맷을 새로운 date&time 포맷으로 변환하기 위한 목적으로 사용되는 노드
- KNIME의 데이터 처리 시스템에서 date&time 관련처리 방식이 업데이트되면서, 기존의 "레거시" 방식으로 저장된 데이터를 새로 채택된 표준 방식으로 변환하기 위해 제공된 도구
<시간 차이 계산(Date&Time Difference)>
- 새로운 date&time 타입의 변수에 대하여 날짜 및 시간의 차이를 계산
<날짜형 to 문자형 변환(Date&Time to String)>
- date&time(time zone 지원) 타입을 문자형 변수로 변환

<문자형 to 날짜형 변환(String to date&time)>
- 문자형 변수를 date&time (time zone 지원) 타입의 변수로 변환

<수치형 to 문자형 변환 (number to string)>
- 수치형 변수를 문자형 변수로 변환
- 데이터 전처리에서 가장 많이 사용하는 노드!!
<문자형 to 수치형 변환 (string to number)>
- 문자형 변수를 수치형 변수로 변환

<실수형 to 정수형 변환(double to int)>
- 실수형 변수 (double)를 정수형 변수(int)로 변환
- 3 options : round (반올림), floor(내림), ceil(올림)

<정규화(normalizer)>
- 수치형 변수의 값을 정규화
- min-max normalization : 최대/최소값을 설정하여 데이터의 분포를 "0~1 사이"로 만듦
- normalization by decimal scaling : 최대값보다 한 자리수 높은 10의 배수로 나누어서 만듦
ex) 122, 11, 130304, 243 이 있다면, 1,000,000로 나누기
- Z-score normalization (Gaussian)
mean of 0 and standard deviation of 1
The same relative distribution as the original data
useful when the data needs to be compared across different scales


<자동 구간화(Auto-binner)>
- 수치형 변수를 여러 구간(bin)으로 그룹화하여 구간 나눔

1) Binning method - Equal
width : 값의 범위를 균일하게 하여 구간 설정
frequency : 행의 개수를 균일하게 하여 구간 설정
2) Binning method - sample quantiles
quantiles : 분위 수를 설정하여 구간을 나누어서 범주화 (결측값이 존재할 경우, 오류 발생)
3) Advanced formatting - output format
standard string : 1.2345E-7
plain string : 0.000000012345
engineering string : 12345E-11

<수치 지정 구간화(numeric binner)>
- 사용자가 직접 구간 수와 각 구간별 범위 설정하여 범주화
- [ ] : 이상 이하 / ] [ : 초과 미만 / [ [ : 이상 미만 / ] ] : 초과 이하


<대소문자 변환(case converter)>

<일정 간격 반복 (interval loop start/loop end)>
- 시작 숫자와 끝 숫자 사이에 일정한 간격을 설정하고 반복 수행


<일정 횟수 반복 (Counting Loop Start/Loop End)>
- 정해진 횟수만큼 반복 수행
<그룹별 반복 (Group Loop Start/Loop End)>
- 데이터의 범주마다 반복 수행
<조건부 멈춤(breakpoint)>
- 반복을 멈추는 조건을 제시

<통계(statistics)>
- 수학적 통계량 출력
- output tables

- statistics table : 통계량 수치 표현

- nominal histogram table : 범주형 변수의 범주별 분포 표현

- occurence table : 각 변수의 범주, 빈도, 빈도 비중 (%) 표현


<빈도 테이블(value counter)>
- 선택한 변수에 해당하는 모든 값의 빈도를 계산한 테이블 생성

<범주 변수별 색상 관리(color manager)>
- 범주형 변수 또는 수치형 변수에 색상 지정하는 노드
- 범주형 변수 : 고유값별로 색상 지정
- 수치형 변수 : 최소 및 최대값 사이의 범위에 따라 색상 지정


<선 그래프 (line plot)>
- 수치형 변수에 대한 line plot 제공 (시계열 데이터 적합)

<막대 그래프 (bar chart)>
- 범주별로 수치를 막대 그래프를 이용하여 표현 (비교 및 패턴 분석)
- category column : x축에 표현할 범주형 변수 선택
- aggregation method : 범주마다 Y값을 집계하는 방식 선택
- manual selection : y축에 포함될 변수 선택


<Pie chart>
- 전체에 대한 각 부분의 비율을 부채꼴 모양으로 표현

<Box plot>
- 데이터 분포를 보여주는 그림으로 이상값 판별을 시각적으로 용이
- 제1사분위(Q1): 데이터의 하위 25%의 위치의 값
- 제2사분위(Q2): 데이터의 하위 50%의 위치의 값으로 중앙값을 의미
- 제3사분위(Q3): 데이터의 하위 75%의 위치의 값
- IQR (Inter-Quantile Range): (Q3 – Q1)의 값
- 최소값[smallest]: (Q1 - 1.5 * IQR)
- 최대값[largest]: (Q3 + 1.5 *IQR)
- 이상값(Outlier)

<conditional box plot>
- 수치 데이터에 따른 범주별 box plot

<scatter plot>

<scatter matrix>
- 산점도 행렬
- 2D 상에 3개 이상의 변수 간 관계 표현

<선형 상관성 (linear correlation)>
- 상관관계 출력
- possible values count : 문자형 변수의 최대 항목 수 설정
- 변수의 항목 수가 지정한 최대값보다 크면 상관계수를 결측값으로 반환

<heatmap>
- 시계열 데이터 또는 범주별 수치 데이터의 상대적인 크기를 색상으로 비교

'Ai' 카테고리의 다른 글
| [Ai] 머신러닝 프로젝트의 주요 단계 프리뷰 (1) (0) | 2025.03.15 |
|---|---|
| [Ai] 머신러닝 시스템의 종류 및 주요 알고리즘 개념 정리 (0) | 2025.03.13 |