
*해당 글은 핸즈온 머신러닝 서적을 바탕으로 정리한 글입니다.
1. 머신러닝 시스템의 종류
머신러닝 시스템의 종류는 다음과 같이 크게 3가지로 분류할 수 있다.
- 훈련 지도 방식 (지도, 비지도, 준지도, 자기 지도, 강화 학습)
- 실시간으로 점진적인 학습을 하는지 아닌지 (온라인 학습과 배치 학습)
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처럼 훈ㄹㄴ 데이터셋에서 패턴을 발견하여 예측 모델을 만드는지 (사례 기반 학습과 모델 기반 학습)
위 범주들은 서로 배타적이지 않고 원하는 대로 연결할 수 있음!
ex) 최첨단 스팸 필터가 심층 신경망 모델을 사용해 스팸과 스팸이 아닌 메일로부터 실시간으로 학습
=> 온라인 & 모델 기반 & 지도 학습 system
1.1 훈련 지도 방식
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 머신러닝 시스템을 학습하는 동안의 "지도 형태"나 "정보량"
1. 지도 학습 (supervised learning)
- 알고리즘에 주입하는 훈련 데이터에 label이라는 원하는 답이 포함됨
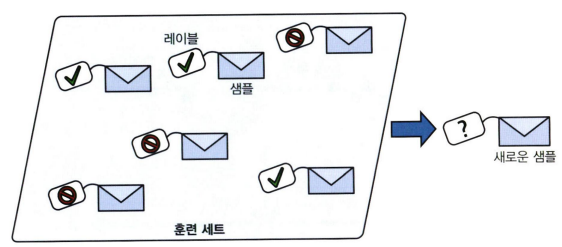
- 분류(classification)가 전형적인 지도 학습 작업
ex) spam filter : 많은 샘플 이메일과 클래스로 훈련되며 어떻게 새 메일을 분류할 지 학습해야 함
- 회귀(regression) : 특성(주행 거리, 연식, 브랜드)을 사용해 중고차 가격 같은 target 수치를 예측하는 행위
=> 해당 시스템을 훈련하려면 특성과 target(중고차 가격)이 포함된 중고차 데이터가 많이 필요함
* target : in 회귀 / label : in 분류
* feature(특성) : predictor(예측 변수) or attribute (속성)
- 일부 회귀 알고리즘을 분류에 사용할 수도 있고, 반대로 일부 분류 알고리즘을 회귀에 사용할 수도 있음
ex) logistic regression -> 클래스에 속할 확률 출력
2. 비지도학습(unsupervised learning)
- 훈련 데이터에 레이블이 없을 때 사용하는 학습 방법으로, 시스템이 아무런 도움 없이 학습해야함


예를 들어 위와 같이 블로그 방문자에 대한 데이터가 많이 있다고 가정해보자.
비슷한 방문자들을 그룹으로 묶기 위해 clustering 알고리즘을 적용하고자 한다.
그러나 방문자가 어떤 그룹에 속하는지 알고리즘에 알려줄 수 있는 정보가 없으므로 알고리즘이 "스스로" 방문자 사이의 연결고리를 찾는다.
ex) 40%의 방문자는 만화책을 좋아하며 방과후에 블로그에 방문하는 10대, 20%는 SF를 좋아하고 주말에 방문하는 성인
이를 위해 hierarchical clustering (계층 군집) 알고리즘을 사용하면 각 그룹을 더 작은 그룹으로 세분화할 수 있음
시각화 알고리즘(visualization)
- 레이블이 없는 대규모의 고차원데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어줌
- 이런 알고리즘은 가능한 "한 구조를 그대로 유지"하려 하므로 데이터가 어떻게 조직되어 있는지 이해할 수 있고 예상하지 못한 패턴을 발견할 수도 있음!
차원 축소(dimensionality reduction)
- 위와 비슷한 작업으로, 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는 방법
- 한 가지 방법: 상관관계가 있는 여러 특성을 하나로 합치는 것
ex) 차의 주행 거리는 연식과 강하게 연관되어 있기 때문에 차원 축소 알고리즘으로 두 특성을 차의 마모 정도를 나타내는 하나의 특성으로 합칠 수 있음 => 특성 추출 (feature extraction)

이상치 탐지(outlier detection)
- ex) 부정 거래를 막기 위해 이상한 신용카드 거래를 탐지하고, 제조 결함을 잡아내고, 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것 등
- 시스템은 훈련하는 동안 대부분 정상 sample을 만나 이를 인식하도록 훈련되고, 그 후 새로운 sample을 보고 정상 or 이상치인지 판단함
ex) 강아지 사진 3000장 중 1%가 치와와 사진이라면, 이상치 탐지 알고리즘은 치와와가 매우 드물고 다른 강아지와 다르다고 인식하여 이상치로 분류할 것
특이치 탐지(novelty detection)
- 이상치 탐지와 매우 비슷한 작업으로, train set에 있는 모든 sample과 달라 보이는 새로운 sample을 탐지하는 것이 목적
=> 따라서 알고리즘으로 감지하고 싶은 샘플을 모두 제거한 매우 "깨끗한" train set이 필요!!
ex) 강아지 사진 3000장 중 1%가 치와와 사진이라면, 특이치 탐지 알고리즘은 새로운 치와와 사진을 특이치로 처리 X
연관 규칙 학습(association rule learning)
- 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 방법
ex) 슈퍼마켓에서 판매 기록에 연관 규칙을 적용하면 바비큐 소스와 감자를 구매한 사람이 스테이크도 구매하는 경향이 있다는 것을 찾을지도 모름 => 이 상품들을 서로 가까이 진열할 수 있을 것!
3. 준지도 학습(semi-supervised learning)
- 데이터에 레이블을 다는 것은 일반적으로 시간과 비용이 많이 들기 때문에, label 없는 샘플이 많고 label된 샘플은 적은 경우가 많음 => label이 일부만 있는 데이터를 다루는 알고리즘이 바로 준지도학습!
ex) 구글 포토 서비스
- 대부분의 준지도 학습 알고리즘 => 지도 학습과 비지도 학습의 조합으로 이루어짐
ex) clustering을 사용해 비슷한 sample을 한 그룹으로 모은 다음, label이 없는 sample에 클러스터에서 가장 많이 등장하는 레이블을 할당하고 전체 데이터셋에 레이블이 부여되고 나면 지도 학습 알고리즘을 사용할 수 있음!
4. 자가 지도 학습(self-supervised learning)
- label이 전혀 없는 데이터셋에서 label이 완전히 부여된 데이터셋을 생성하는 것
- 여기서도 전체 데이터셋에 label이 부여되고 나면 어떤 지도 학습 알고리즘도 사용 가능!

- label이 없는 이미지로 구성된 대량의 데이터셋이 있는 경우 => 각 이미지의 일부분을 랜덤하게 masking하고 모델이 원본 이미지를 복원하도록 훈련 가능!
- 훈련하는 동안 마스킹된 이미지는 모델의 입력으로 사용되고 원본 이미지는 레이블로 사용됨
- 훈련된 모델을 그 자체로 매우 유용하다.
ex) 손상된 이미지 복원, 사진에서 원치 않는 물체 삭제
- 그러나 종종 자기 지도 학습을 사용해 훈련된 모델이 최종 목적이 아닌 경우가 많음
- 일반적으로 조금 다르지만 실제 관심 대상인 작업을 위해 모델을 수정하거나 fine tuning
** 전이 학습(transfer learning) : 한 작업에서 다른 작업으로 지식을 전달하는 것
=> 주로 심층 신경망(neural network)에서 가장 중요한 기술
- 자가지도 학습은 label이 전혀 없는 데이터셋을 사용하기 때문에 비지도 학습의 일부라고 생각할 수 있지만, 훈련하는 동안 (생성된) label을 사용하기 때문에 지도 학습에 더 가까움!
=> 따라서 자가 지도 학습 또한 지도 학습과 동일한 작업 (주로 분류와 회귀)에 초점을 맞춤
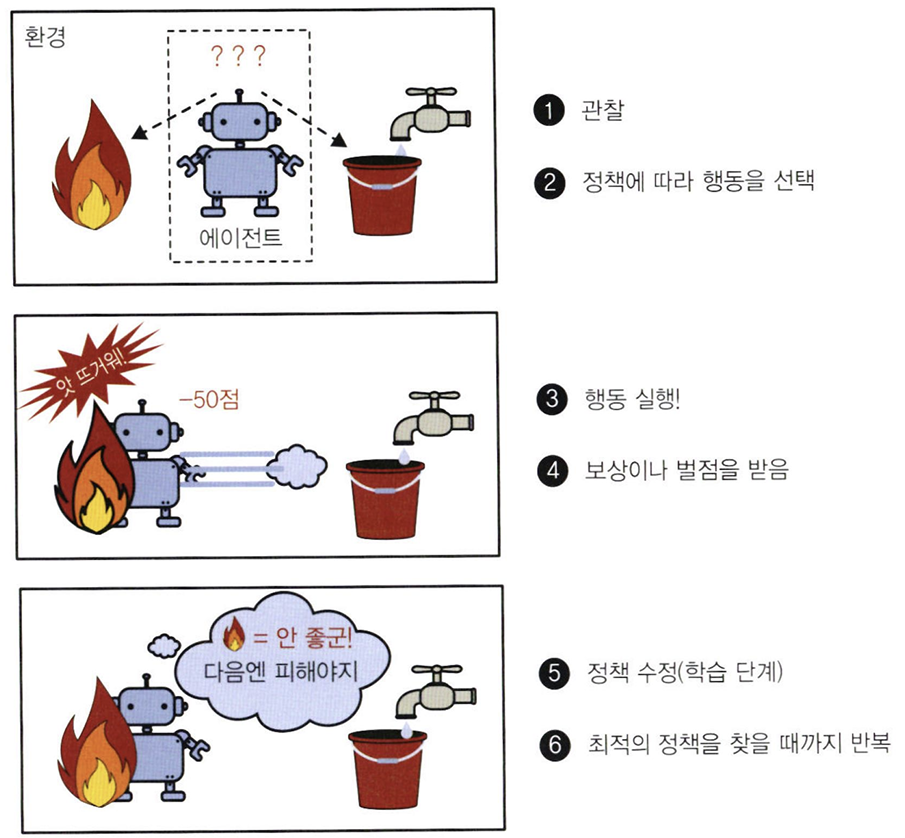
5. 강화 학습(reinforcement learning)
- 여기서 학습하는 시스템은 agent라고 부르며, environment를 관찰해서 action을 실행하고 그 결과로 reward 또는 penalty를 받음
- 시간이 지나면서 가장 큰 보상을 얻기 위해 policy라고 부르는 최상의 전략을 스스로 학습
- 정책은 주어진 상황에서 agent가 어떤 행동을 선택해야 할지 정의함
ex) 알파고 시스템 -> 자기 자신과 많은 게임을 하면서 승리 전략을 학습한 뒤, 챔피언과 게임할 때는 학습 기능을 끄고 그동한 학습했던 전략을 적용함 (오프라인 학습)
1.2 배치 학습과 온라인 학습
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 입력 데이터의 stream으로부터 점진적으로 학습할 수 있는지 여부
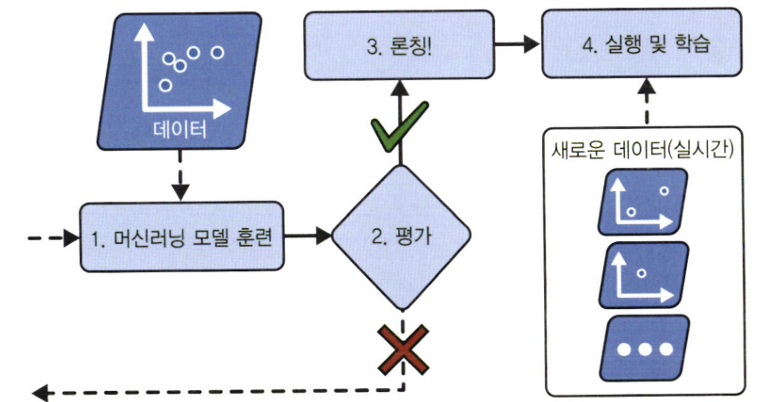
1. 배치 학습(batch learning)
- 배치 학습에서는 시스템이 점진적 학습 X
=> 가용한 데이터를 "모두 사용"해 훈련시켜야 함
- 일반적으로 이 방식은 시간과 자원을 많이 소모하므로 오프라인에서 수행됨
- 먼저 시스템을 훈련시킨 다음, 제품 시스템에 적용하면 더 이상의 학습 없이 실행됨 => offline learning
* 모델 부패(model rot) / 데이터 드리프트(data drift)
- 세상은 계속 진화하는데 모델은 바뀌지 않고 그대로인 이유로 모델의 성능이 시간이 지남에 따라 천천히 감소하는 경향
- 해결책 : 최신 데이터에서 모델을 정기적으로 재훈련
Q. 배치 학습 시스템이 새로운 데이터에 대해 학습하는 방법?
1. 전체 데이터(new data + previous data)를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 함
2. 그 후 이전 모델을 새 모델로 교체
3. 머신러닝 시스템을 훈련, 평가, 론칭하여 업데이트
- 이는 간단하고 잘 작동하지만 전체 데이터셋을 사용해 훈련하는 데 몇 시간이 소요될 수 있으며, 보통 24시간마다 또는 매주 시스템을 훈련시킴 => 주식가격 같은 빠르게 변동하는 데이터에 적응해야 한다면 더 능동적인 방법 필요!
- 전체 데이터셋을 사용해 훈련한다면 많은 컴퓨팅 자원이 필요
- 자원이 제한된 시스템 (ex: 화성 탐사)이 많은 양의 훈련 데이터를 나르고 매일 몇 시간씩 학습을 위해 많은 자원을 사용하면 심각한 문제를 일으킴
이러한 경우 다음과 같이 점진적으로 학습할 수 있는 알고리즘을 사용하는 편이 낫다.
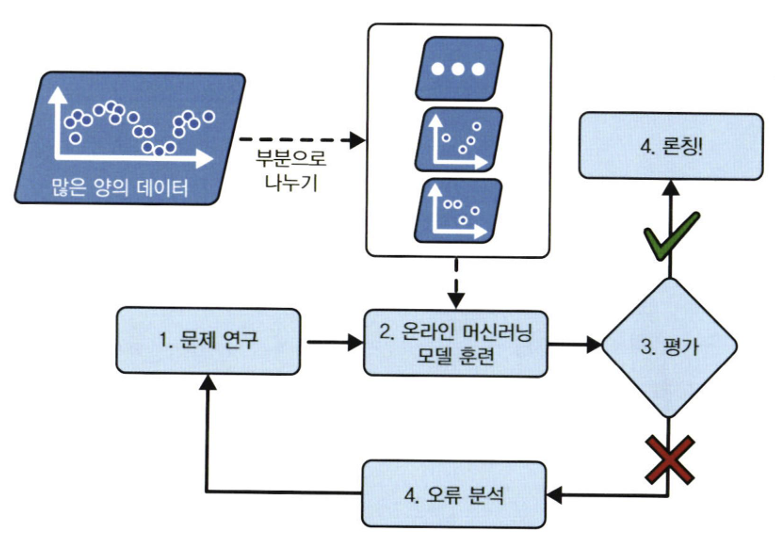
2. 온라인 학습(online learning) - 점진적 학습
- 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킴
- 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있음
- 학습률(learning rate) : 변화하는 데이터에 얼마나 빠르게 적응할 것인지를 나타내는 온라인 학습 시스템에서 중요한 파라미터
=> high : 시스템이 데이터에 빠르게 적응하지만 예전 데이터 금방 잊어버릴 가능성
=> low : 시스템의 관성이 더 커져서 더 느리게 학습되지만 새로운 데이터에 있는 잡음이나 대표성 없는 데이터 포인트에 덜 민감해짐
Q. 온라인 학습의 가장 큰 문제점?
- 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 감소 ex) 버그, 검색어 조작
- 데이터 품질과 학습률에 따라서 빠르게 감소할 가능성
- 해결책 : 면밀한 시스템 모니터링 도중 성능 감소가 감지되면 즉각 학습 중지 or 이상치 탐지 알고리즘
1.3 사례기반 학습과 모델 기반 학습
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 어떻게 "일반화"(generalization)되는가
- 훈련 데이터에서 높은 성능을 내는 것도 중요하지만...새로운 데이터에서 잘 예측하는 것이 중요
- 진짜 목표 : "새로운 샘플에 잘 작동"하는 모델!!
1. 사례 기반 학습
- 시스템이 훈련 샘플을 "기억"함으로써 학습한 뒤, 유사도 측정을 사용해 new data와 학습한 sample을 비교하는 식으로 일반화하는 방법
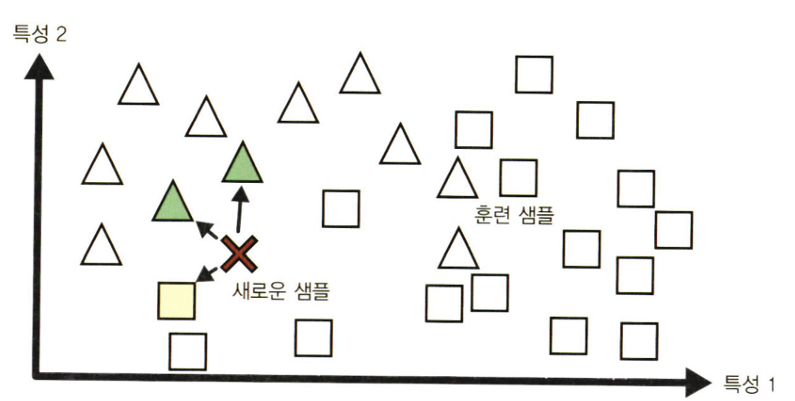
ex) 스팸 메일 분류
- 스팸 메일 분류 시 스팸 메일과 매우 유사한 메일 사이의 유사도(similarity)를 측정해야 한다.
- 두 메일 사이의 유사도는 공통으로 포함된 단어의 수를 세면 되며, 이 때 공통되는 단어가 많으면 스팸으로 분류
2. 모델 기반 학습
- 이 샘플들의 모델을 만들어 "예측"에 사용하는 방법
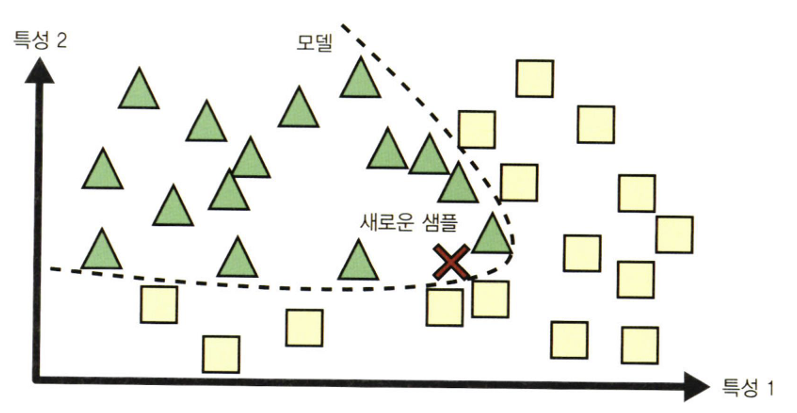
*효용 함수(utility function) : 모델이 얼마나 좋은지 측정하는 함수
*비용 함수(cost function) : 모델이 얼마나 나쁜지 측정하는 함수
=> 선형 회귀에서는 보통 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 이 cost function을 사용하며, 이 거리를 최소화하는 것이 목표!
*모델 훈련 : 훈련 데이터에 가장 잘 맞고 새로운 데이터에 좋은 예측을 만들 수 있는 모델 파라미터를 찾기 위해 알고리즘을 실행하는 것
2. 머신러닝의 주요 도전 과제
<나쁜 데이터>
1. 충분하지 않은 양의 훈련 데이터
- 대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 함
- 아주 간단한 문제에서도 수천 개의 데이터가 필요하고, 이미지나 음성 인식 같은 복잡한 문제라면 수백만 개가 필요할지도 모름
2. 대표성 없는 훈련 데이터
- 일반화가 잘되려면 훈련 데이터가 일반화하고 싶은 새로운 사례를 잘 대표하는 것이 중요
- 샘플링 편향(sampling bias) : 샘플이 작으면 sampling noise가 생기고, 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수도 있음
3. 낮은 품질의 데이터
- 훈련 데이터가 오류, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 패턴을 찾기 어렵기 때문에, 데이터 정제에 많은 시간을 쏟아야 한다.
<훈련 데이터 정제가 필요한 경우>
- 일부 샘플이 이상치라는 것이 명확한 경우 : 샘플 무시 or 수동으로 잘못된 것 고치기
- 일부 샘플에 특성 몇 개가 빠져있는 경우 : 특성 자체를 모두 무시 or 샘플을 무시 or 빠진 값 채우기 etc
4. 관련 없는 특성
*특성 공학(feature engineering)
- 특성 선택(feature selection) : 갖고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택
- 특성 추출(feature extraction) : 특성을 결합하여 더 유용한 특성 만듦 ex) 차원 축소 알고리즘
- 데이터 수집 : 새로운 데이터를 수집해 새 특성 만들기
<나쁜 알고리즘>
5. 훈련 데이터 과대적합
- 과대적합(overfitting) : 모델이 훈련 데이터에는 너무 잘 맞지만 일반성이 떨어진다는 뜻
- 주로 훈련 데이터의 양과 잡음에 비해 모델이 너무 복잡할 때 발생
Q. 해결책?
1) 파라미터 수가 적은 모델을 선택 / 훈련 데이터에 있는 특성 수 줄이기 / 모델 단순화
2) 훈련 데이터를 더 많이 모으기
3) 훈련 데이터의 잡음 줄이기
- 규제(regularization) : 모델을 단순하게 하고 과대적합의 위험을 줄이기 위해 모델에 제약을 가하는 것
- 선형 모델에 두 개의 모델 파라미터 θ0, θ1이 있을 때, 훈련 데이터에 모델을 맞추기 위한 두 개의 자유도(degree of freedom)를 학습 알고리즘에 부여
=> 모델이 직선의 절편(θ0), 기울기(θ1)를 조절할 수 있음
- 데이터를 완벽히 맞추는 것과 일반화를 위해 단순한 모델을 유지하는 것 사이의 올바른 균형을 찾는 것이 좋음
- 하이퍼파라미터(hyperparameter) : 학습 알고리즘의 파라미터로, 학습하는 동안 적용할 "규제의 양"을 결정
=> 학습 알고리즘으로부터 영향을 받지 않고, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아있음
6. 훈련 데이터 과소적합
- 과소적합(underfitting) : 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생
Q. 해결책?
- 모델 파라미터가 더 많은 강력한 모델을 선택
- 학습 알고리즘에 더 좋은 특성을 제공(특성 공학)
- 모델의 제약 줄이기 (hyperparameter 감소)
3. 테스트와 검증
- 모델이 새로운 샘플에 얼마나 잘 일반화될지 알 수 있는 유일한 방법 : 새로운 샘플에 실제로 적용해보기!
- 더 나은 방법 : 훈련 데이터를 train, test set 두 개로 나누는 것
- 새로운 샘플에 대한 오차 비율을 일반화 오차(generalization error)라고 하며, test set에서 모델을 평가함으로써 이 오차에 대한 estimation을 얻음
=> 이 값은 이전에 본 적이 없는 새로운 샘플에 모델이 얼마나 잘 작동할지 알려줌
- 훈련 오차가 작지만 일반화 오차가 크다면 이는 모델이 훈련 데이터에 과대적합 되었다는 뜻!
3.1 하이퍼파라미터 튜닝과 모델 선택
- 모델 평가는 그냥 test set를 사용하면 되지만, test set에서 일반화 오차를 여러 번 측정하면 모델과 하이퍼파라미터가 test set에 최적화된모델을 만들기 때문에 모델이 새로운 데이터에 잘 작동하지 않을 수 있음
=> 이를 해결하기 위해 홀드아웃 검증(holdout validation) 사용!
- 훈련 세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택
=>이 새로운 홀드아웃 세트를 검증 세트(validation set)라고부름
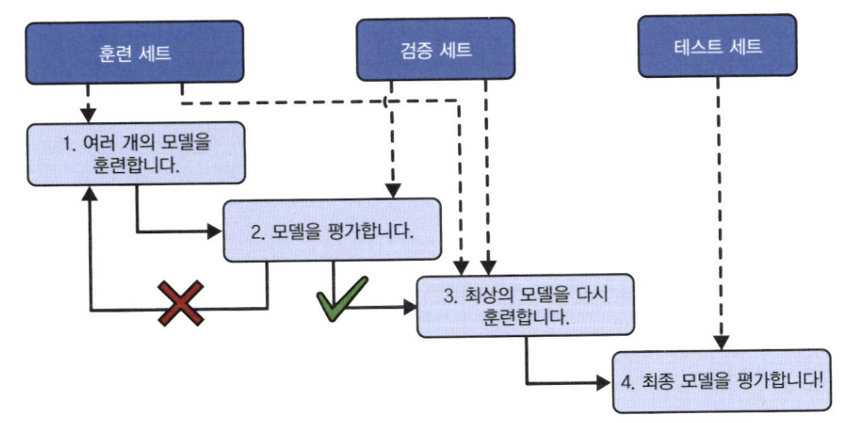
그러나 위 검증 방법의 경우, 최종 모델이 전체 훈련 세트에서 훈련되기 때문에 너무 작은 훈련 세트에서 훈련한 후보 모델을 비교하는 것은 이상적이지 않다.
따라서 작은 검증 세트 여러 개를 사용해 반복적인 교차 검증(cross-validation)을 수행함!
3.2 데이터 불일치
- 훈련-개발 세트(train-dev set) : 훈련 사진의 일부를 떼어내 또 다른 세트를 만드는 것
- 모델을 훈련 세트에서 훈련한 다음, 훈련-개발 세트에서 평가
=> 이 때 모델이 잘 작동하지 않으면 훈련 세트에 과대적합 된 것이라고 판단 가능
=> 더 많은 훈련 데이터를 모으거나 데이터 정제 필요.
=> BUT 훈련-개발 세트에서 잘 작동한다면 검증 세트에서 평가 가능
=> 만약 성능이 나쁘다면 이는 "데이터 불일치" 때문! (추가 전처리 필요)
'Ai' 카테고리의 다른 글
| [Ai] 머신러닝 프로젝트의 주요 단계 프리뷰 (1) (0) | 2025.03.15 |
|---|---|
| [Ai] KNIME 사용법 및 각종 노드 활용 방법 모음 (0) | 2025.01.16 |
*해당 글은 핸즈온 머신러닝 서적을 바탕으로 정리한 글입니다.
1. 머신러닝 시스템의 종류
머신러닝 시스템의 종류는 다음과 같이 크게 3가지로 분류할 수 있다.
- 훈련 지도 방식 (지도, 비지도, 준지도, 자기 지도, 강화 학습)
- 실시간으로 점진적인 학습을 하는지 아닌지 (온라인 학습과 배치 학습)
- 단순하게 알고 있는 데이터 포인트와 새 데이터 포인트를 비교하는 것인지 아니면 과학자들이 하는 것처럼 훈ㄹㄴ 데이터셋에서 패턴을 발견하여 예측 모델을 만드는지 (사례 기반 학습과 모델 기반 학습)
위 범주들은 서로 배타적이지 않고 원하는 대로 연결할 수 있음!
ex) 최첨단 스팸 필터가 심층 신경망 모델을 사용해 스팸과 스팸이 아닌 메일로부터 실시간으로 학습
=> 온라인 & 모델 기반 & 지도 학습 system
1.1 훈련 지도 방식
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 머신러닝 시스템을 학습하는 동안의 "지도 형태"나 "정보량"
1. 지도 학습 (supervised learning)
- 알고리즘에 주입하는 훈련 데이터에 label이라는 원하는 답이 포함됨
- 분류(classification)가 전형적인 지도 학습 작업
ex) spam filter : 많은 샘플 이메일과 클래스로 훈련되며 어떻게 새 메일을 분류할 지 학습해야 함
- 회귀(regression) : 특성(주행 거리, 연식, 브랜드)을 사용해 중고차 가격 같은 target 수치를 예측하는 행위
=> 해당 시스템을 훈련하려면 특성과 target(중고차 가격)이 포함된 중고차 데이터가 많이 필요함
* target : in 회귀 / label : in 분류
* feature(특성) : predictor(예측 변수) or attribute (속성)
- 일부 회귀 알고리즘을 분류에 사용할 수도 있고, 반대로 일부 분류 알고리즘을 회귀에 사용할 수도 있음
ex) logistic regression -> 클래스에 속할 확률 출력
2. 비지도학습(unsupervised learning)
- 훈련 데이터에 레이블이 없을 때 사용하는 학습 방법으로, 시스템이 아무런 도움 없이 학습해야함
예를 들어 위와 같이 블로그 방문자에 대한 데이터가 많이 있다고 가정해보자.
비슷한 방문자들을 그룹으로 묶기 위해 clustering 알고리즘을 적용하고자 한다.
그러나 방문자가 어떤 그룹에 속하는지 알고리즘에 알려줄 수 있는 정보가 없으므로 알고리즘이 "스스로" 방문자 사이의 연결고리를 찾는다.
ex) 40%의 방문자는 만화책을 좋아하며 방과후에 블로그에 방문하는 10대, 20%는 SF를 좋아하고 주말에 방문하는 성인
이를 위해 hierarchical clustering (계층 군집) 알고리즘을 사용하면 각 그룹을 더 작은 그룹으로 세분화할 수 있음
시각화 알고리즘(visualization)
- 레이블이 없는 대규모의 고차원데이터를 넣으면 도식화가 가능한 2D나 3D 표현을 만들어줌
- 이런 알고리즘은 가능한 "한 구조를 그대로 유지"하려 하므로 데이터가 어떻게 조직되어 있는지 이해할 수 있고 예상하지 못한 패턴을 발견할 수도 있음!
차원 축소(dimensionality reduction)
- 위와 비슷한 작업으로, 너무 많은 정보를 잃지 않으면서 데이터를 간소화하는 방법
- 한 가지 방법: 상관관계가 있는 여러 특성을 하나로 합치는 것
ex) 차의 주행 거리는 연식과 강하게 연관되어 있기 때문에 차원 축소 알고리즘으로 두 특성을 차의 마모 정도를 나타내는 하나의 특성으로 합칠 수 있음 => 특성 추출 (feature extraction)
이상치 탐지(outlier detection)
- ex) 부정 거래를 막기 위해 이상한 신용카드 거래를 탐지하고, 제조 결함을 잡아내고, 학습 알고리즘에 주입하기 전에 데이터셋에서 이상한 값을 자동으로 제거하는 것 등
- 시스템은 훈련하는 동안 대부분 정상 sample을 만나 이를 인식하도록 훈련되고, 그 후 새로운 sample을 보고 정상 or 이상치인지 판단함
ex) 강아지 사진 3000장 중 1%가 치와와 사진이라면, 이상치 탐지 알고리즘은 치와와가 매우 드물고 다른 강아지와 다르다고 인식하여 이상치로 분류할 것
특이치 탐지(novelty detection)
- 이상치 탐지와 매우 비슷한 작업으로, train set에 있는 모든 sample과 달라 보이는 새로운 sample을 탐지하는 것이 목적
=> 따라서 알고리즘으로 감지하고 싶은 샘플을 모두 제거한 매우 "깨끗한" train set이 필요!!
ex) 강아지 사진 3000장 중 1%가 치와와 사진이라면, 특이치 탐지 알고리즘은 새로운 치와와 사진을 특이치로 처리 X
연관 규칙 학습(association rule learning)
- 대량의 데이터에서 특성 간의 흥미로운 관계를 찾는 방법
ex) 슈퍼마켓에서 판매 기록에 연관 규칙을 적용하면 바비큐 소스와 감자를 구매한 사람이 스테이크도 구매하는 경향이 있다는 것을 찾을지도 모름 => 이 상품들을 서로 가까이 진열할 수 있을 것!
3. 준지도 학습(semi-supervised learning)
- 데이터에 레이블을 다는 것은 일반적으로 시간과 비용이 많이 들기 때문에, label 없는 샘플이 많고 label된 샘플은 적은 경우가 많음 => label이 일부만 있는 데이터를 다루는 알고리즘이 바로 준지도학습!
ex) 구글 포토 서비스
- 대부분의 준지도 학습 알고리즘 => 지도 학습과 비지도 학습의 조합으로 이루어짐
ex) clustering을 사용해 비슷한 sample을 한 그룹으로 모은 다음, label이 없는 sample에 클러스터에서 가장 많이 등장하는 레이블을 할당하고 전체 데이터셋에 레이블이 부여되고 나면 지도 학습 알고리즘을 사용할 수 있음!
4. 자가 지도 학습(self-supervised learning)
- label이 전혀 없는 데이터셋에서 label이 완전히 부여된 데이터셋을 생성하는 것
- 여기서도 전체 데이터셋에 label이 부여되고 나면 어떤 지도 학습 알고리즘도 사용 가능!
- label이 없는 이미지로 구성된 대량의 데이터셋이 있는 경우 => 각 이미지의 일부분을 랜덤하게 masking하고 모델이 원본 이미지를 복원하도록 훈련 가능!
- 훈련하는 동안 마스킹된 이미지는 모델의 입력으로 사용되고 원본 이미지는 레이블로 사용됨
- 훈련된 모델을 그 자체로 매우 유용하다.
ex) 손상된 이미지 복원, 사진에서 원치 않는 물체 삭제
- 그러나 종종 자기 지도 학습을 사용해 훈련된 모델이 최종 목적이 아닌 경우가 많음
- 일반적으로 조금 다르지만 실제 관심 대상인 작업을 위해 모델을 수정하거나 fine tuning
** 전이 학습(transfer learning) : 한 작업에서 다른 작업으로 지식을 전달하는 것
=> 주로 심층 신경망(neural network)에서 가장 중요한 기술
- 자가지도 학습은 label이 전혀 없는 데이터셋을 사용하기 때문에 비지도 학습의 일부라고 생각할 수 있지만, 훈련하는 동안 (생성된) label을 사용하기 때문에 지도 학습에 더 가까움!
=> 따라서 자가 지도 학습 또한 지도 학습과 동일한 작업 (주로 분류와 회귀)에 초점을 맞춤
5. 강화 학습(reinforcement learning)
- 여기서 학습하는 시스템은 agent라고 부르며, environment를 관찰해서 action을 실행하고 그 결과로 reward 또는 penalty를 받음
- 시간이 지나면서 가장 큰 보상을 얻기 위해 policy라고 부르는 최상의 전략을 스스로 학습
- 정책은 주어진 상황에서 agent가 어떤 행동을 선택해야 할지 정의함
ex) 알파고 시스템 -> 자기 자신과 많은 게임을 하면서 승리 전략을 학습한 뒤, 챔피언과 게임할 때는 학습 기능을 끄고 그동한 학습했던 전략을 적용함 (오프라인 학습)
1.2 배치 학습과 온라인 학습
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 입력 데이터의 stream으로부터 점진적으로 학습할 수 있는지 여부
1. 배치 학습(batch learning)
- 배치 학습에서는 시스템이 점진적 학습 X
=> 가용한 데이터를 "모두 사용"해 훈련시켜야 함
- 일반적으로 이 방식은 시간과 자원을 많이 소모하므로 오프라인에서 수행됨
- 먼저 시스템을 훈련시킨 다음, 제품 시스템에 적용하면 더 이상의 학습 없이 실행됨 => offline learning
* 모델 부패(model rot) / 데이터 드리프트(data drift)
- 세상은 계속 진화하는데 모델은 바뀌지 않고 그대로인 이유로 모델의 성능이 시간이 지남에 따라 천천히 감소하는 경향
- 해결책 : 최신 데이터에서 모델을 정기적으로 재훈련
Q. 배치 학습 시스템이 새로운 데이터에 대해 학습하는 방법?
1. 전체 데이터(new data + previous data)를 사용하여 시스템의 새로운 버전을 처음부터 다시 훈련해야 함
2. 그 후 이전 모델을 새 모델로 교체
3. 머신러닝 시스템을 훈련, 평가, 론칭하여 업데이트
- 이는 간단하고 잘 작동하지만 전체 데이터셋을 사용해 훈련하는 데 몇 시간이 소요될 수 있으며, 보통 24시간마다 또는 매주 시스템을 훈련시킴 => 주식가격 같은 빠르게 변동하는 데이터에 적응해야 한다면 더 능동적인 방법 필요!
- 전체 데이터셋을 사용해 훈련한다면 많은 컴퓨팅 자원이 필요
- 자원이 제한된 시스템 (ex: 화성 탐사)이 많은 양의 훈련 데이터를 나르고 매일 몇 시간씩 학습을 위해 많은 자원을 사용하면 심각한 문제를 일으킴
이러한 경우 다음과 같이 점진적으로 학습할 수 있는 알고리즘을 사용하는 편이 낫다.
2. 온라인 학습(online learning) - 점진적 학습
- 데이터를 순차적으로 한 개씩 또는 미니배치라 부르는 작은 묶음 단위로 주입하여 시스템을 훈련시킴
- 매 학습 단계가 빠르고 비용이 적게 들어 시스템은 데이터가 도착하는 대로 즉시 학습할 수 있음
- 학습률(learning rate) : 변화하는 데이터에 얼마나 빠르게 적응할 것인지를 나타내는 온라인 학습 시스템에서 중요한 파라미터
=> high : 시스템이 데이터에 빠르게 적응하지만 예전 데이터 금방 잊어버릴 가능성
=> low : 시스템의 관성이 더 커져서 더 느리게 학습되지만 새로운 데이터에 있는 잡음이나 대표성 없는 데이터 포인트에 덜 민감해짐
Q. 온라인 학습의 가장 큰 문제점?
- 시스템에 나쁜 데이터가 주입되었을 때 시스템 성능이 감소 ex) 버그, 검색어 조작
- 데이터 품질과 학습률에 따라서 빠르게 감소할 가능성
- 해결책 : 면밀한 시스템 모니터링 도중 성능 감소가 감지되면 즉각 학습 중지 or 이상치 탐지 알고리즘
1.3 사례기반 학습과 모델 기반 학습
- 머신러닝 시스템을 분류할 때 사용하는 또 다른 기준 : 어떻게 "일반화"(generalization)되는가
- 훈련 데이터에서 높은 성능을 내는 것도 중요하지만...새로운 데이터에서 잘 예측하는 것이 중요
- 진짜 목표 : "새로운 샘플에 잘 작동"하는 모델!!
1. 사례 기반 학습
- 시스템이 훈련 샘플을 "기억"함으로써 학습한 뒤, 유사도 측정을 사용해 new data와 학습한 sample을 비교하는 식으로 일반화하는 방법
ex) 스팸 메일 분류
- 스팸 메일 분류 시 스팸 메일과 매우 유사한 메일 사이의 유사도(similarity)를 측정해야 한다.
- 두 메일 사이의 유사도는 공통으로 포함된 단어의 수를 세면 되며, 이 때 공통되는 단어가 많으면 스팸으로 분류
2. 모델 기반 학습
- 이 샘플들의 모델을 만들어 "예측"에 사용하는 방법
*효용 함수(utility function) : 모델이 얼마나 좋은지 측정하는 함수
*비용 함수(cost function) : 모델이 얼마나 나쁜지 측정하는 함수
=> 선형 회귀에서는 보통 선형 모델의 예측과 훈련 데이터 사이의 거리를 재는 이 cost function을 사용하며, 이 거리를 최소화하는 것이 목표!
*모델 훈련 : 훈련 데이터에 가장 잘 맞고 새로운 데이터에 좋은 예측을 만들 수 있는 모델 파라미터를 찾기 위해 알고리즘을 실행하는 것
2. 머신러닝의 주요 도전 과제
<나쁜 데이터>
1. 충분하지 않은 양의 훈련 데이터
- 대부분의 머신러닝 알고리즘이 잘 작동하려면 데이터가 많아야 함
- 아주 간단한 문제에서도 수천 개의 데이터가 필요하고, 이미지나 음성 인식 같은 복잡한 문제라면 수백만 개가 필요할지도 모름
2. 대표성 없는 훈련 데이터
- 일반화가 잘되려면 훈련 데이터가 일반화하고 싶은 새로운 사례를 잘 대표하는 것이 중요
- 샘플링 편향(sampling bias) : 샘플이 작으면 sampling noise가 생기고, 매우 큰 샘플도 표본 추출 방법이 잘못되면 대표성을 띠지 못할 수도 있음
3. 낮은 품질의 데이터
- 훈련 데이터가 오류, 이상치, 잡음으로 가득하다면 머신러닝 시스템이 패턴을 찾기 어렵기 때문에, 데이터 정제에 많은 시간을 쏟아야 한다.
<훈련 데이터 정제가 필요한 경우>
- 일부 샘플이 이상치라는 것이 명확한 경우 : 샘플 무시 or 수동으로 잘못된 것 고치기
- 일부 샘플에 특성 몇 개가 빠져있는 경우 : 특성 자체를 모두 무시 or 샘플을 무시 or 빠진 값 채우기 etc
4. 관련 없는 특성
*특성 공학(feature engineering)
- 특성 선택(feature selection) : 갖고 있는 특성 중에서 훈련에 가장 유용한 특성을 선택
- 특성 추출(feature extraction) : 특성을 결합하여 더 유용한 특성 만듦 ex) 차원 축소 알고리즘
- 데이터 수집 : 새로운 데이터를 수집해 새 특성 만들기
<나쁜 알고리즘>
5. 훈련 데이터 과대적합
- 과대적합(overfitting) : 모델이 훈련 데이터에는 너무 잘 맞지만 일반성이 떨어진다는 뜻
- 주로 훈련 데이터의 양과 잡음에 비해 모델이 너무 복잡할 때 발생
Q. 해결책?
1) 파라미터 수가 적은 모델을 선택 / 훈련 데이터에 있는 특성 수 줄이기 / 모델 단순화
2) 훈련 데이터를 더 많이 모으기
3) 훈련 데이터의 잡음 줄이기
- 규제(regularization) : 모델을 단순하게 하고 과대적합의 위험을 줄이기 위해 모델에 제약을 가하는 것
- 선형 모델에 두 개의 모델 파라미터 θ0, θ1이 있을 때, 훈련 데이터에 모델을 맞추기 위한 두 개의 자유도(degree of freedom)를 학습 알고리즘에 부여
=> 모델이 직선의 절편(θ0), 기울기(θ1)를 조절할 수 있음
- 데이터를 완벽히 맞추는 것과 일반화를 위해 단순한 모델을 유지하는 것 사이의 올바른 균형을 찾는 것이 좋음
- 하이퍼파라미터(hyperparameter) : 학습 알고리즘의 파라미터로, 학습하는 동안 적용할 "규제의 양"을 결정
=> 학습 알고리즘으로부터 영향을 받지 않고, 훈련 전에 미리 지정되고, 훈련하는 동안에는 상수로 남아있음
6. 훈련 데이터 과소적합
- 과소적합(underfitting) : 모델이 너무 단순해서 데이터의 내재된 구조를 학습하지 못할 때 발생
Q. 해결책?
- 모델 파라미터가 더 많은 강력한 모델을 선택
- 학습 알고리즘에 더 좋은 특성을 제공(특성 공학)
- 모델의 제약 줄이기 (hyperparameter 감소)
3. 테스트와 검증
- 모델이 새로운 샘플에 얼마나 잘 일반화될지 알 수 있는 유일한 방법 : 새로운 샘플에 실제로 적용해보기!
- 더 나은 방법 : 훈련 데이터를 train, test set 두 개로 나누는 것
- 새로운 샘플에 대한 오차 비율을 일반화 오차(generalization error)라고 하며, test set에서 모델을 평가함으로써 이 오차에 대한 estimation을 얻음
=> 이 값은 이전에 본 적이 없는 새로운 샘플에 모델이 얼마나 잘 작동할지 알려줌
- 훈련 오차가 작지만 일반화 오차가 크다면 이는 모델이 훈련 데이터에 과대적합 되었다는 뜻!
3.1 하이퍼파라미터 튜닝과 모델 선택
- 모델 평가는 그냥 test set를 사용하면 되지만, test set에서 일반화 오차를 여러 번 측정하면 모델과 하이퍼파라미터가 test set에 최적화된모델을 만들기 때문에 모델이 새로운 데이터에 잘 작동하지 않을 수 있음
=> 이를 해결하기 위해 홀드아웃 검증(holdout validation) 사용!
- 훈련 세트의 일부를 떼어내어 여러 후보 모델을 평가하고 가장 좋은 하나를 선택
=>이 새로운 홀드아웃 세트를 검증 세트(validation set)라고부름
그러나 위 검증 방법의 경우, 최종 모델이 전체 훈련 세트에서 훈련되기 때문에 너무 작은 훈련 세트에서 훈련한 후보 모델을 비교하는 것은 이상적이지 않다.
따라서 작은 검증 세트 여러 개를 사용해 반복적인 교차 검증(cross-validation)을 수행함!
3.2 데이터 불일치
- 훈련-개발 세트(train-dev set) : 훈련 사진의 일부를 떼어내 또 다른 세트를 만드는 것
- 모델을 훈련 세트에서 훈련한 다음, 훈련-개발 세트에서 평가
=> 이 때 모델이 잘 작동하지 않으면 훈련 세트에 과대적합 된 것이라고 판단 가능
=> 더 많은 훈련 데이터를 모으거나 데이터 정제 필요.
=> BUT 훈련-개발 세트에서 잘 작동한다면 검증 세트에서 평가 가능
=> 만약 성능이 나쁘다면 이는 "데이터 불일치" 때문! (추가 전처리 필요)
'Ai' 카테고리의 다른 글
| [Ai] 머신러닝 프로젝트의 주요 단계 프리뷰 (1) (0) | 2025.03.15 |
|---|---|
| [Ai] KNIME 사용법 및 각종 노드 활용 방법 모음 (0) | 2025.01.16 |